How NVIDIA’s Puzzle Framework Redefines Language Model Optimization for Scalable AI
- Cost-Effective AI Scalability: NVIDIA’s Puzzle framework tackles the growing issue of high inference costs in large language models (LLMs), making state-of-the-art capabilities more accessible.
- Architectural Innovation: Puzzle combines Neural Architecture Search (NAS) with blockwise local distillation (BLD) to optimize LLMs specifically for their deployment hardware, achieving unparalleled efficiency.
- Real-World Impact: Nemotron-51B, an optimized model derived from Llama-3.1-70B, showcases Puzzle’s ability to preserve nearly all of a model’s accuracy while more than doubling its inference throughput.
As AI adoption grows, large language models such as GPT and LLaMA set new standards for accuracy and capabilities. However, their deployment is restricted by high inference costs, requiring vast computational resources. Traditionally, increasing parameter counts boosts model performance but exacerbates scalability issues, creating a chasm between state-of-the-art capabilities and practical utility.
The industry’s pursuit of Artificial General Intelligence (AGI) has further fueled this trend, with models becoming increasingly larger and complex. Yet, this size-centric focus risks leaving smaller enterprises and applications behind due to prohibitive deployment costs.
Puzzle: A Paradigm Shift in LLM Optimization
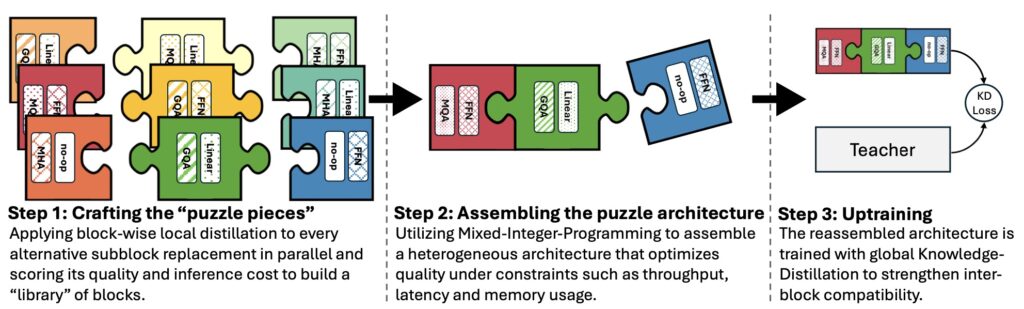
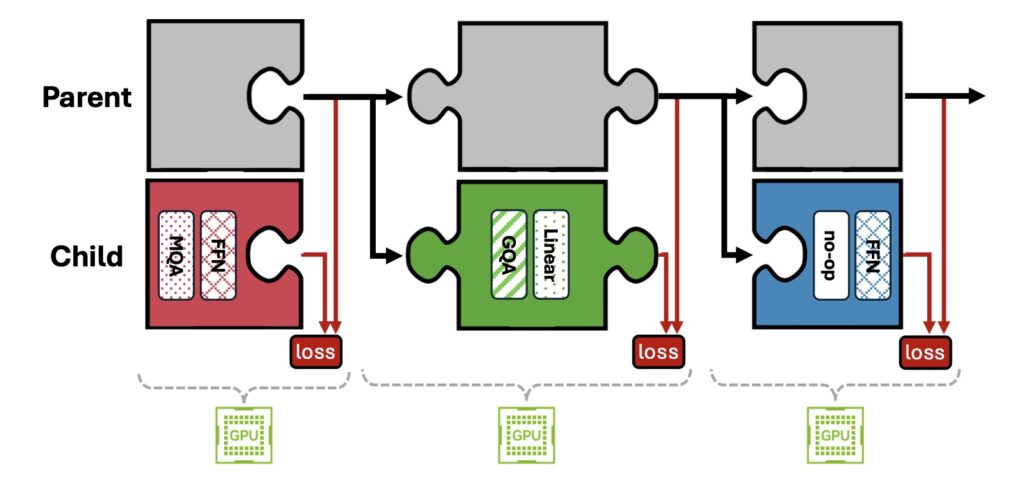
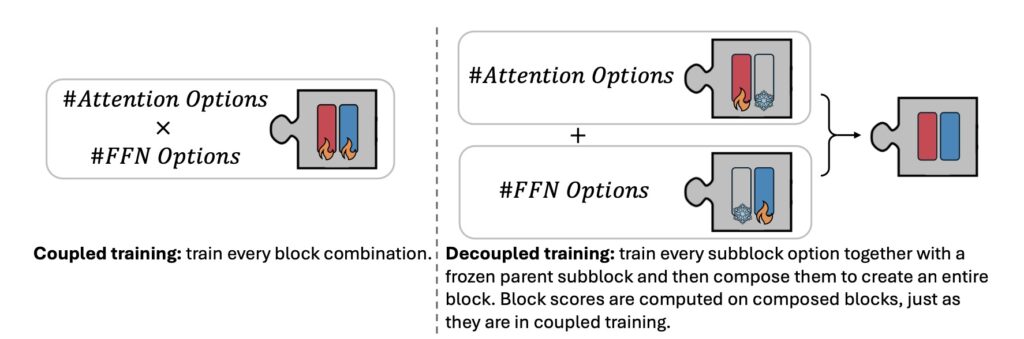
NVIDIA introduces the Puzzle framework, a novel solution to bridge this gap. Puzzle employs neural architecture search (NAS) at an unprecedented scale to systematically optimize LLMs under hardware constraints. Its core innovation lies in blockwise local knowledge distillation (BLD), a technique that enables efficient parallel exploration of architectural changes without retraining from scratch.
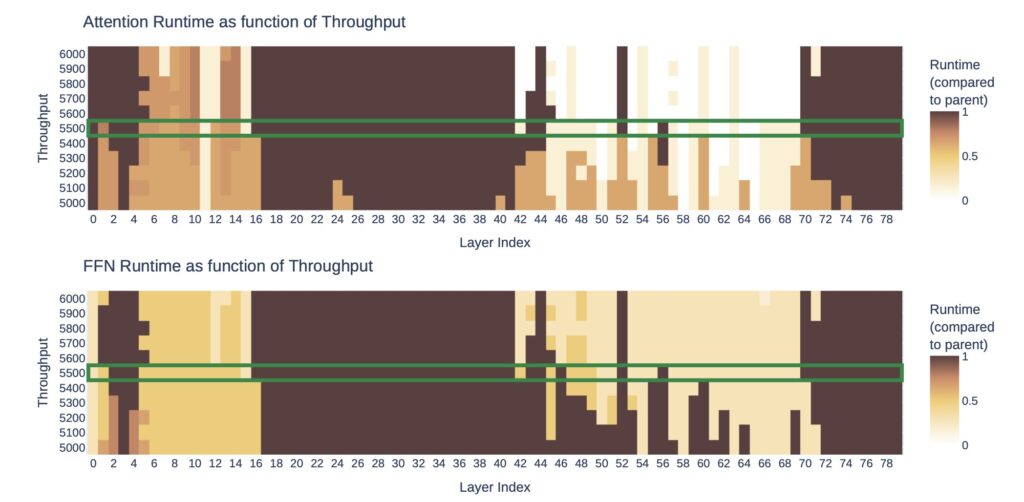
Using mixed-integer programming (MIP), Puzzle precisely aligns model architectures with specific hardware requirements. This method diverges from the conventional notion of maintaining uniform architectures across training and inference, challenging long-standing assumptions in AI development.
Nemotron-51B: A Case Study in Efficiency
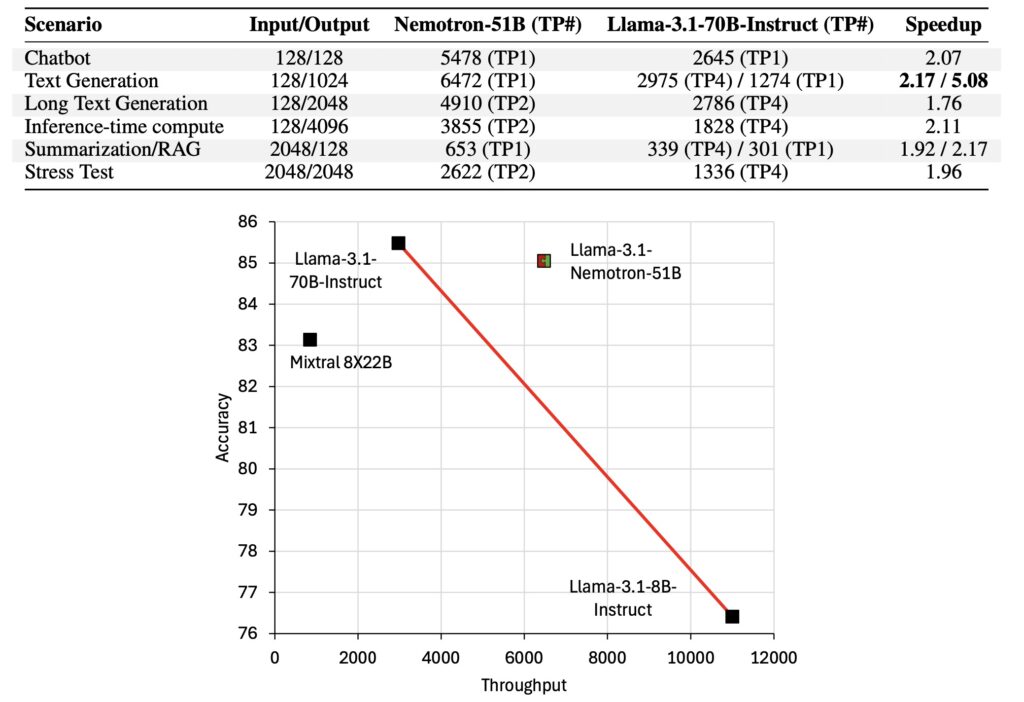
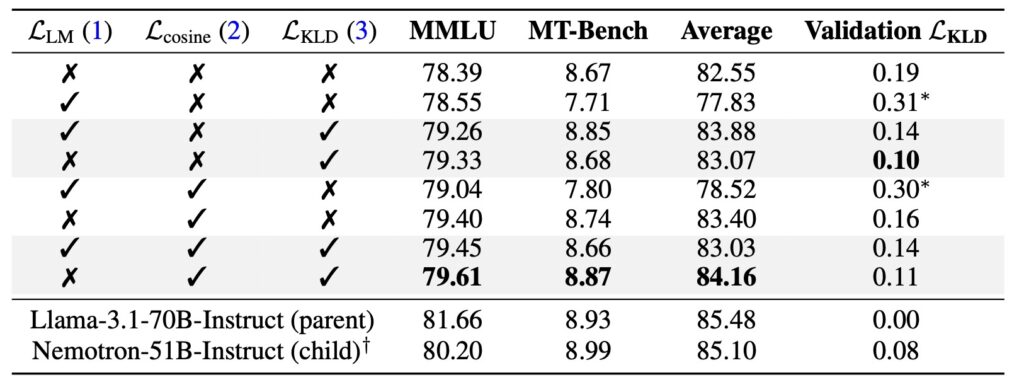
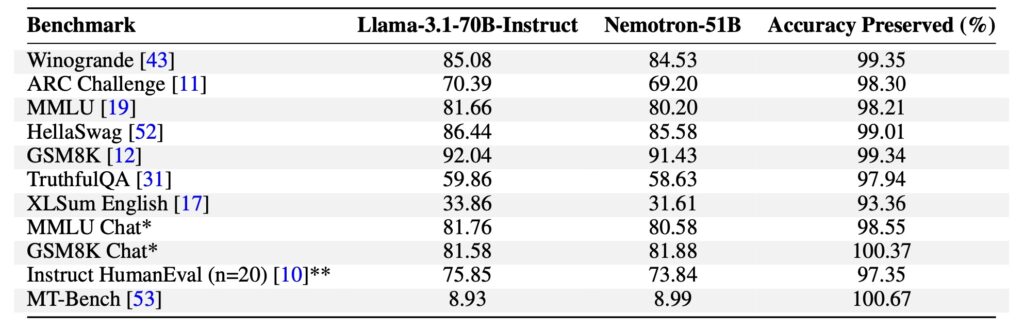
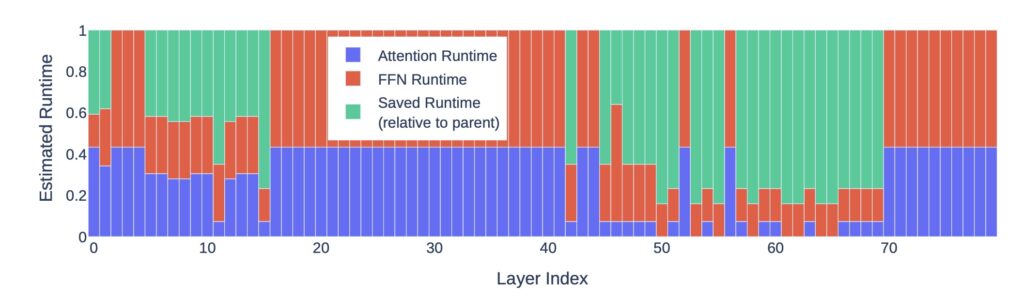
The effectiveness of Puzzle is exemplified by Nemotron-51B, a model derived from LLaMA-3.1-70B-Instruct. Through Puzzle’s optimization, Nemotron-51B achieves:
- 2.17x inference throughput speedup on a single NVIDIA H100 GPU.
- 98.4% capability retention compared to its parent model.
- Deployment efficiency that supports large batch sizes on a single GPU.
What sets Nemotron-51B apart is the minimal resource requirement for its transformation—just 45 billion tokens, a fraction of the trillions typically required. This efficiency dramatically reduces the cost and complexity of producing high-performing AI models.
Future Directions for Puzzle
Puzzle’s success paves the way for transformative research opportunities:
- Architectural Innovations: Exploring alternative building blocks, such as variable window attention or state-space models, to further enhance optimization.
- Capability-Specific Optimization: Tailoring models for specialized tasks like Chain-of-Thought reasoning, multimodal applications, or retrieval-augmented generation.
- Advanced Search Algorithms: Incorporating reinforcement learning or evolutionary techniques for more sophisticated architecture discovery.
- Robustness and Adaptability: Studying how Puzzle-optimized models handle distribution shifts and adapt to novel tasks through fine-tuning.
These advancements could enable AI systems to balance precision and efficiency across diverse use cases, from data centers to edge devices.
Implications for AI Deployment
Puzzle redefines how we think about AI scalability. By decoupling model size from deployment efficiency, it empowers organizations to adopt powerful AI systems without excessive computational demands. This paradigm shift prioritizes inference performance over parameter count, aligning model capabilities with practical constraints.
The broader adoption of Puzzle could lead to democratized AI deployment, reducing barriers for smaller enterprises and enabling efficient solutions for real-world problems. As a result, advanced LLMs could transition from experimental tools to mainstream assets in domains like virtual assistants, enterprise automation, and beyond.
NVIDIA’s Puzzle framework represents a significant leap toward making cutting-edge language models more accessible and cost-effective. By focusing on inference optimization rather than parameter expansion, Puzzle provides a roadmap for scalable, efficient, and high-performing AI systems. With models like Nemotron-51B setting new benchmarks, the framework underscores a future where AI can meet real-world demands without compromising on capability or affordability.