How a Strategic Partnership with DeepSeek R1 on Blackwell Architecture is Driving 25x Revenue Growth and Redefining AI Efficiency
- Nvidia’s collaboration with DeepSeek R1 on Blackwell GPUs has unlocked a 25x revenue surge and 20x cost reduction in AI inference.
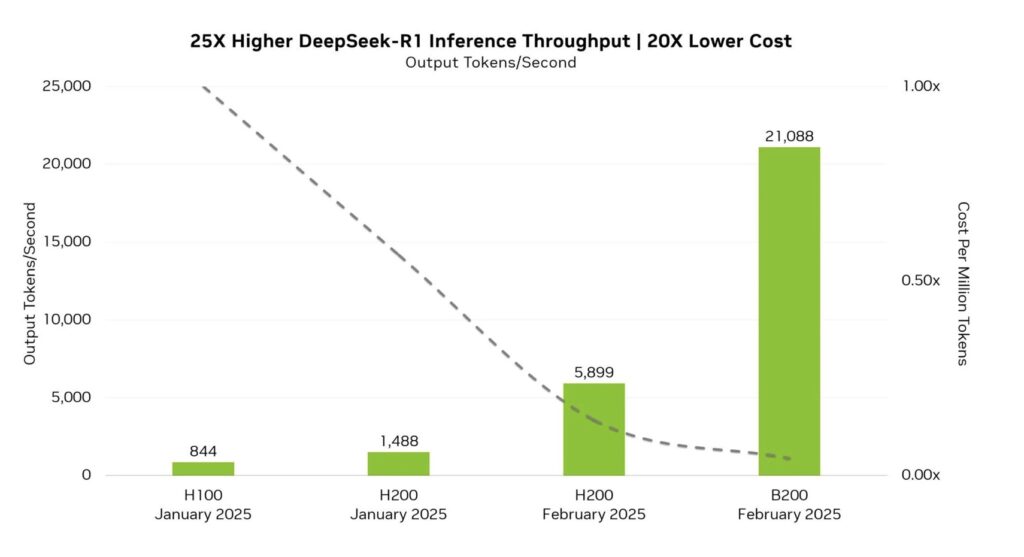
- The Blackwell B200 GPU achieves 21,088 tokens per second, dwarfing previous models like the H100 and H200.
- Open-source models and FP4 precision are driving a new era of accessible, affordable, and high-performance AI.
As tech giants like OpenAI and Alibaba push to outpace rivals with ever-larger AI models, Nvidia is charting a different course. Instead of battling startups like DeepSeek, the semiconductor titan is embracing collaboration. By optimizing DeepSeek’s R1 model for its Blackwell architecture, Nvidia isn’t just accelerating AI performance—it’s rewriting the rules of the game. The result? A staggering 25x revenue boost and a blueprint for democratizing AI’s future.
The Power of Partnership: From Rivals to Revenue
When DeepSeek’s AI model debuted, critics warned it could disrupt legacy players. But Nvidia saw opportunity. “Inference requires significant numbers of NVIDIA GPUs,” a company spokesperson noted, framing DeepSeek’s rise as a win-win. Fast-forward to today: the Blackwell-optimized DeepSeek R1 partnership has turned potential competition into a revenue rocket.
By leveraging FP4 precision—a low-bit computing format that slashes power use while maintaining 99.8% of FP8’s accuracy—Nvidia’s B200 GPUs now process data faster and cheaper than ever. Imagine an AI service generating $100,000 in revenue at $50,000 cost. Post-optimization, revenue soars to $2.5 million, while costs plummet to $2,500. The result? $2.49 million in profit—a margin that reshapes business models industry-wide.
Blackwell B200: A Quantum Leap in AI Processing
Nvidia’s performance charts tell a seismic story. The Blackwell B200 GPU processes 21,088 tokens per second, a figure that eclipses the H200’s 5,899 tokens (Feb. 2025) and the H100’s 844 tokens (Jan. 2025). This isn’t just incremental growth—it’s a paradigm shift.
For developers, the implications are profound. Nvidia has already released an FP4-optimized DeepSeek checkpoint, giving innovators early access to these efficiency gains. “DeepSeek’s open approach is a game-changer,” one expert noted, highlighting how collaborative models can outpace closed ecosystems.
Democratizing AI: Open Models and Efficiency Innovations
While rivals hoard proprietary tech, Nvidia and DeepSeek are betting on openness. By sharing optimized models publicly, they’re inviting developers worldwide to build atop their infrastructure—a stark contrast to the walled gardens of OpenAI or Alibaba.
FP4 is central to this vision. Though lower precision risks accuracy dips, Nvidia’s benchmarks show near-parity with FP8, proving efficiency needn’t sacrifice quality. This breakthrough makes high-performance AI accessible to startups and researchers, not just tech titans.
Why Fight When You Can Lead?
Nvidia’s playbook is clear: in a sector obsessed with competition, collaboration fuels progress. By aligning with DeepSeek, the company isn’t just selling GPUs—it’s cultivating an ecosystem where its hardware thrives. As AI races toward ubiquity, Nvidia’s blend of open innovation and cutting-edge engineering positions it not as a participant, but as a pioneer. The message to rivals? Adaptation beats antagonism—every time.