A Hybrid Model That Balances Speed, Cost, and Advanced Thinking for Developers
- Gemini 2.5 Flash, now in preview, introduces a hybrid reasoning model through the Gemini API, Google AI Studio, and Vertex AI, building on the speed of 2.0 Flash with enhanced reasoning capabilities.
- Developers gain unprecedented control with adjustable thinking budgets, allowing tailored tradeoffs between quality, cost, and latency for diverse use cases.
- From simple queries to complex problem-solving, Gemini 2.5 Flash excels across reasoning levels, positioning it as a cost-efficient leader in AI performance.
Today marks an exciting milestone for developers and AI enthusiasts as we roll out an early preview of Gemini 2.5 Flash, a groundbreaking iteration of our popular 2.0 Flash model. Available through the Gemini API via Google AI Studio and Vertex AI, as well as in a dedicated dropdown in the Gemini app, this version is not just an upgrade—it’s a reinvention. Building on the foundation of speed and affordability that made 2.0 Flash a favorite, Gemini 2.5 Flash introduces a fully hybrid reasoning capability, empowering developers to toggle thinking on or off and customize performance like never before. This model isn’t just about answering prompts; it’s about reasoning through them, breaking down complex tasks, and delivering thoughtful, accurate responses.
What sets Gemini 2.5 Flash apart is its ability to perform a deliberate “thinking” process before generating outputs. Unlike traditional models that rush to respond, this version can analyze a prompt, dissect multi-step challenges, and plan its answer. Whether it’s solving intricate math problems, crafting detailed schedules, or tackling engineering calculations, the thinking process ensures higher accuracy and depth. In fact, on Hard Prompts in LMArena, Gemini 2.5 Flash ranks second only to 2.5 Pro, proving its prowess in handling sophisticated queries while maintaining a competitive edge in cost and speed.
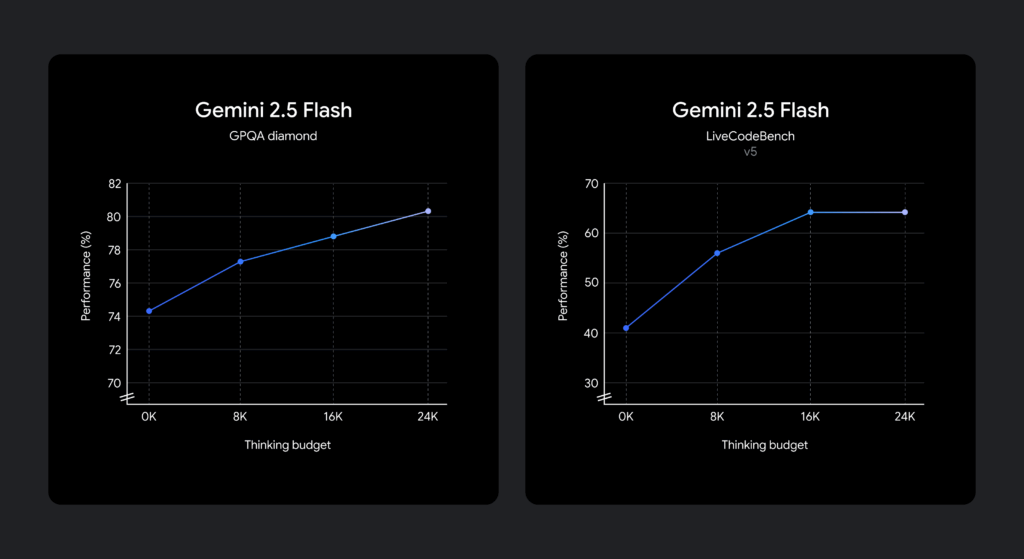
One of the most innovative features of Gemini 2.5 Flash is the introduction of a thinking budget—a fine-grained control mechanism that lets developers set a cap on the number of tokens the model uses during its reasoning phase. This budget, adjustable from 0 to 24,576 tokens, offers flexibility to balance quality, cost, and latency based on specific needs. Want the lowest cost and fastest response? Set the budget to 0 and still enjoy improved performance over 2.0 Flash. Need deeper reasoning for a complex task? Increase the budget to allow more extensive thinking. Remarkably, the model is trained to assess task complexity and only uses as much of the budget as necessary, ensuring efficiency without sacrificing results. Developers can tweak this parameter via the API, a slider in Google AI Studio, or Vertex AI, making it accessible for experimentation.
The versatility of Gemini 2.5 Flash shines through in its handling of prompts across varying levels of reasoning. For low-reasoning tasks, such as translating “Thank you” into Spanish or stating the number of provinces in Canada, the model responds swiftly with minimal deliberation. Medium-reasoning prompts, like calculating the probability of two dice summing to 7 or scheduling basketball hours around a 9-to-6 workweek, showcase its ability to break down logical steps efficiently. For high-reasoning challenges, the model truly flexes its muscles—whether it’s computing the maximum bending stress on a cantilever beam with specific dimensions and loads or writing a function to evaluate spreadsheet cells with dependency resolution and cycle detection, Gemini 2.5 Flash delivers precise, well-thought-out solutions.
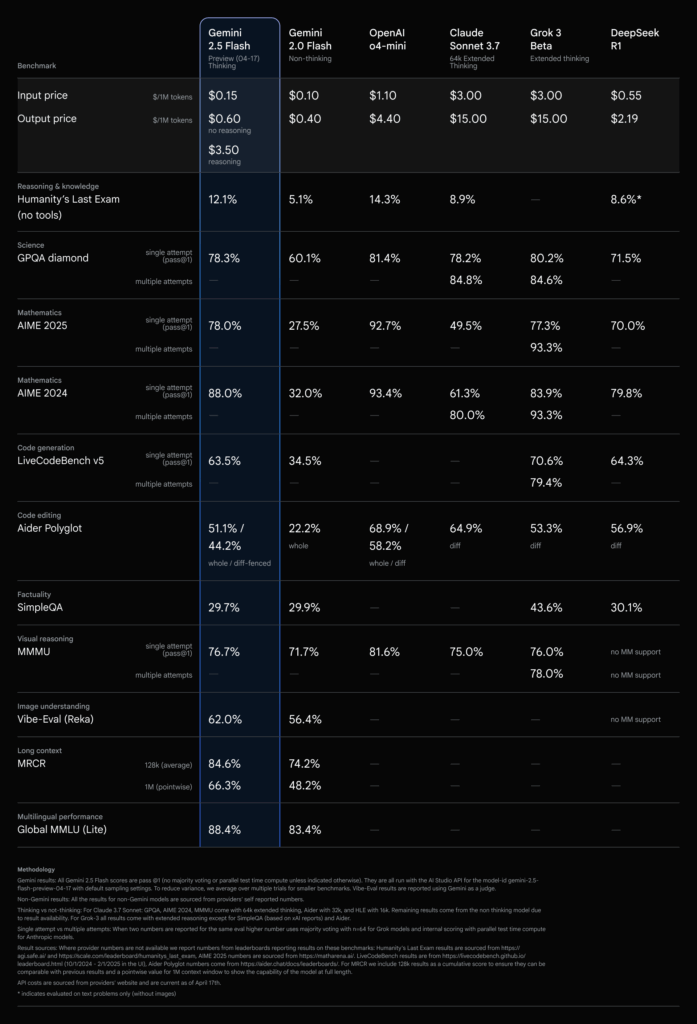
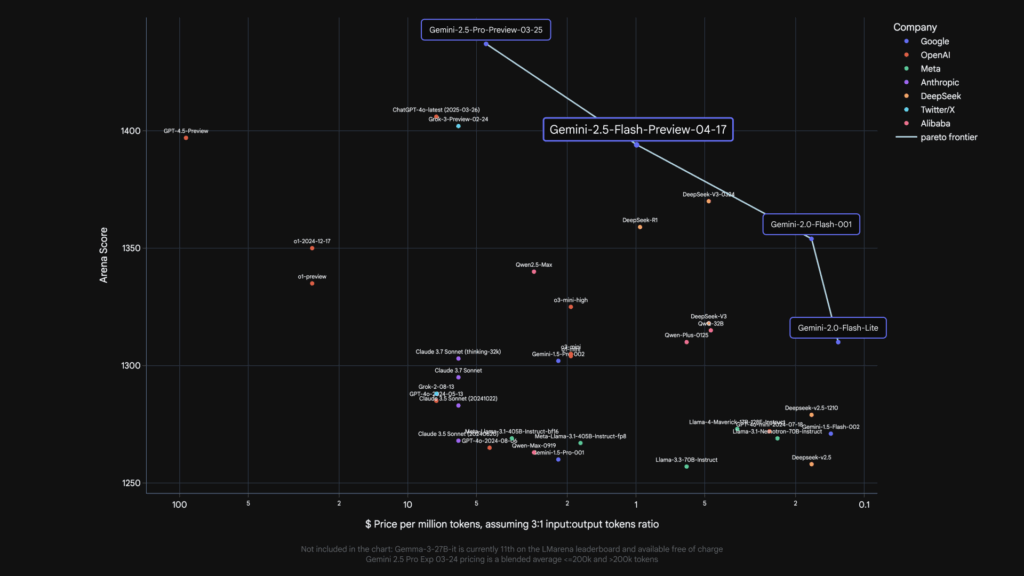
Beyond its technical capabilities, Gemini 2.5 Flash continues to lead as the most cost-efficient thinking model in our lineup. It offers the best price-to-performance ratio, making advanced AI accessible to a broader range of developers and businesses. This affordability, combined with customizable thinking controls, positions it as a game-changer for use cases spanning from quick customer service responses to in-depth research analysis. The model’s hybrid nature means you don’t have to choose between speed and quality—you can have both, tailored to your project’s demands.
We invite developers to dive into Gemini 2.5 Flash today and explore its potential. Experiment with the thinking_budget parameter to see how controllable reasoning can elevate your applications, whether you’re solving everyday queries or pushing the boundaries of complex problem-solving. Detailed API references, thinking guides, and code examples are available in our developer docs and the Gemini Cookbook to help you get started. While this preview is just the beginning, we’re committed to refining and expanding the model’s capabilities before its full production release. More updates and enhancements are on the horizon, and we can’t wait to see how the developer community leverages this powerful tool to build the next generation of AI-driven solutions.