Llama 4 Maverick 400B Achieves Over 2,500 Tokens Per Second, Redefining AI Performance
- Cerebras Systems has set a world record for LLM inference speed, achieving over 2,500 tokens per second (TPS) per user on the 400B parameter Llama 4 Maverick model, more than doubling NVIDIA Blackwell’s performance of 1,038 TPS.
- Independent benchmark firm Artificial Analysis confirmed Cerebras as the only vendor to outperform NVIDIA’s flagship solution, with other competitors like SambaNova, Amazon, Groq, Google, and Microsoft trailing significantly.
- With immediate availability and no need for custom optimizations, Cerebras Inference API positions itself as the optimal solution for enterprise AI applications, addressing critical latency bottlenecks in reasoning, code generation, and agentic workflows.
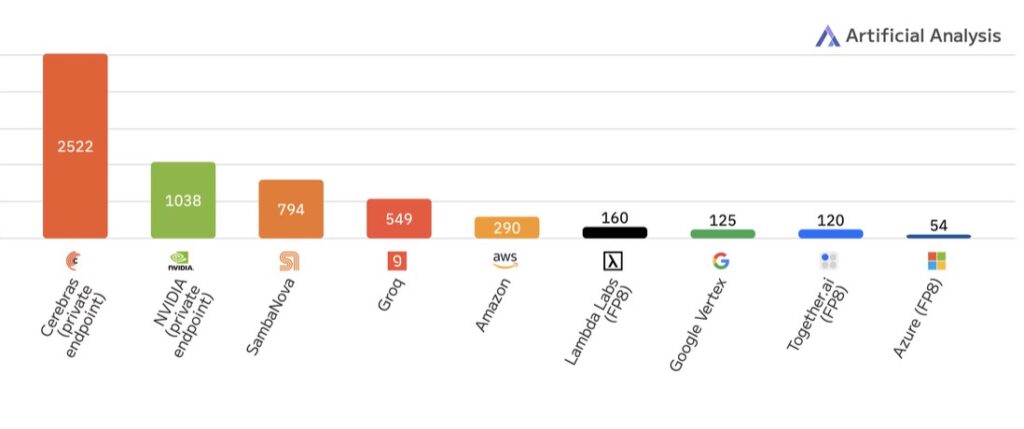
On May 28, 2025, in Sunnyvale, CA, Cerebras Systems made headlines by shattering the inference speed record for large language models (LLMs) with a staggering performance of over 2,500 tokens per second (TPS) per user on Meta’s Llama 4 Maverick 400B, the largest and most powerful model in the Llama 4 family. This achievement, measured by the independent benchmark firm Artificial Analysis, more than doubles the performance of NVIDIA’s recently announced Blackwell GPUs in a DGX B200 setup, which clocked in at 1,038 TPS per user just last week. Micah Hill-Smith, Co-Founder and CEO of Artificial Analysis, emphasized the significance of this milestone, stating that Cerebras is the only inference solution among dozens of tested vendors to surpass NVIDIA’s flagship technology for Meta’s premier model.
The implications of this record are profound for the AI industry, where inference speed is often the bottleneck for real-world deployment of cutting-edge applications. Cerebras’ CEO, Andrew Feldman, highlighted the critical need for speed in enterprise AI, noting that applications like agents, code generation, and complex reasoning suffer from latency issues on traditional GPU setups. He pointed out that generation speeds as low as 100 TPS on GPUs can result in wait times of minutes, rendering production deployment impractical for many businesses. Cerebras, however, has consistently pushed the boundaries of inference performance across multiple models, including Llama, DeepSeek, and Qwen, regularly delivering over 2,500 TPS per user and setting a new standard for the industry.
What sets Cerebras apart is not just its raw performance but also its accessibility and efficiency. Unlike NVIDIA’s Blackwell setup, which relied on custom software optimizations unavailable to most users and reportedly operated at less than 1% GPU utilization due to reduced batch sizes, Cerebras achieved its record-breaking results without any special kernel tweaks. Moreover, while NVIDIA’s published performance of 1,000 TPS isn’t reflected in any of its inference providers’ services, Cerebras’ hardware and API are available now, with plans for integration into Meta’s API service in the near future. This immediate availability makes Cerebras a practical choice for developers and enterprises looking to deploy high-speed AI solutions without delay.
Artificial Analysis’ comprehensive testing of other vendors further underscores Cerebras’ dominance in this space. Competitors like SambaNova managed 794 TPS, Groq reached 549 TPS, Amazon hit 290 TPS, Google lagged at 125 TPS, and Microsoft Azure trailed with just 54 TPS on the same Llama 4 Maverick model. These results paint a clear picture: Cerebras is not just leading the pack—it’s redefining what’s possible in AI inference performance.
The importance of speed in AI cannot be overstated, especially for applications that rely on processing large volumes of tokens to deliver intelligent responses. Whether it’s reasoning tasks, voice interactions, or agentic workflows, the ability to generate answers quickly directly impacts user experience and business outcomes. As Google demonstrated with search engine performance over a decade ago, even small delays can drive users to competitors who offer faster results. Cerebras’ breakthrough ensures that enterprises no longer have to compromise between intelligence and speed, providing a solution that excels in both.
For developers and enterprise AI users worldwide, Cerebras stands out as the optimal choice for deploying Llama 4 Maverick in any scenario. Its record-breaking performance, combined with immediate availability and a commitment to accessibility through upcoming API integrations, positions Cerebras as a game-changer in the AI landscape. As the industry continues to evolve, Cerebras’ leadership in inference speed signals a future where latency is no longer a barrier to innovation, empowering businesses to harness the full potential of advanced AI models without the frustration of long wait times.