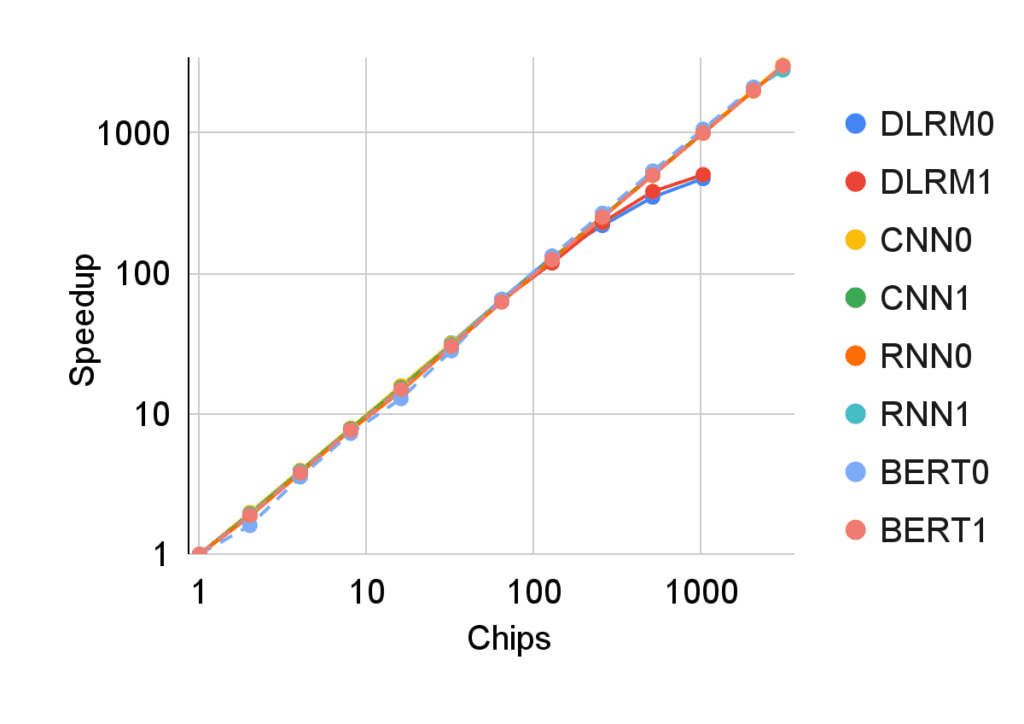
The TPU v4 offers almost a 10x leap in scaling ML system performance compared to TPU v3, making it more energy-efficient and reducing CO2e by up to 20x.
Google engineers Norm Jouppi and David Patterson have unveiled the key innovations behind the Cloud TPU v4, Google’s latest Tensor Processing Unit (TPU), which has become a popular choice for AI researchers and developers for training machine learning models at scale. The TPU v4 boasts significant improvements in performance, scalability, efficiency, and sustainability.
The TPU v4 offers almost a 10x leap in scaling ML system performance compared to TPU v3, making it more energy-efficient and reducing CO2e by up to 20x. These advancements make TPU v4 an ideal choice for large language models. The TPU v4 system consists of 4096 chips interconnected by an internally developed, industry-leading optical circuit switch (OCS), providing exascale ML performance.
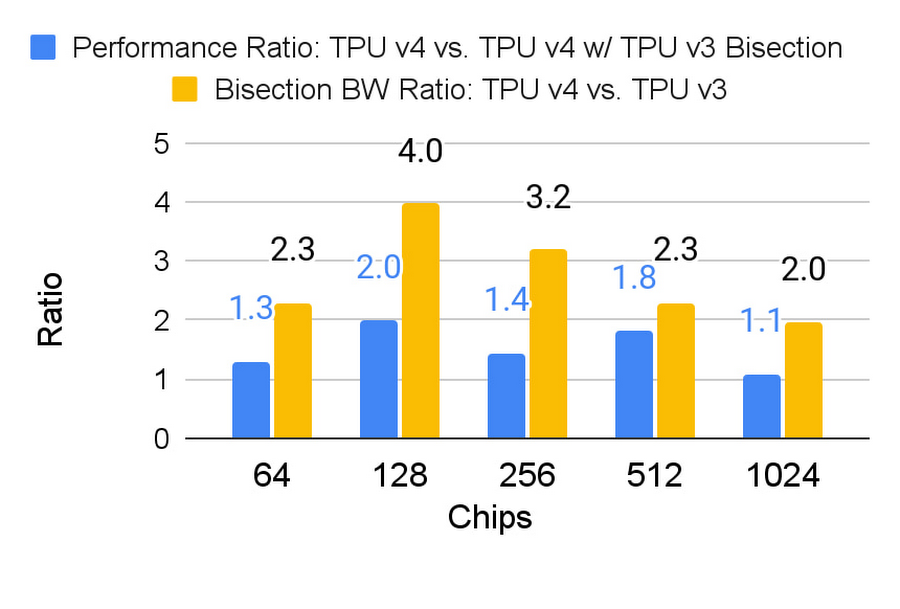
The TPU v4 outperforms its predecessor, the TPU v3, by 2.1x on a per-chip basis and improves performance/Watt by 2.7x. The reconfigurable OCS in TPU v4 contributes to improved scale, availability, utilization, modularity, deployment, security, power, and performance, while using less than 5% of the system’s cost and power.


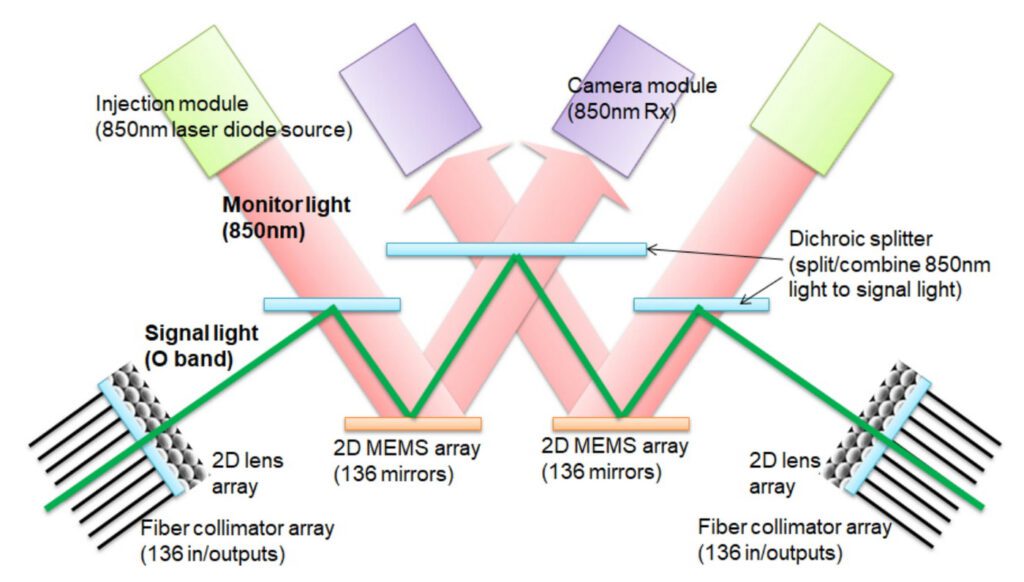
Dynamic OCS reconfigurability enhances the TPU’s availability, making it easy to route around failed components during long-running tasks like ML training. This flexibility allows for changes in the supercomputer interconnect’s topology to boost an ML model’s performance.
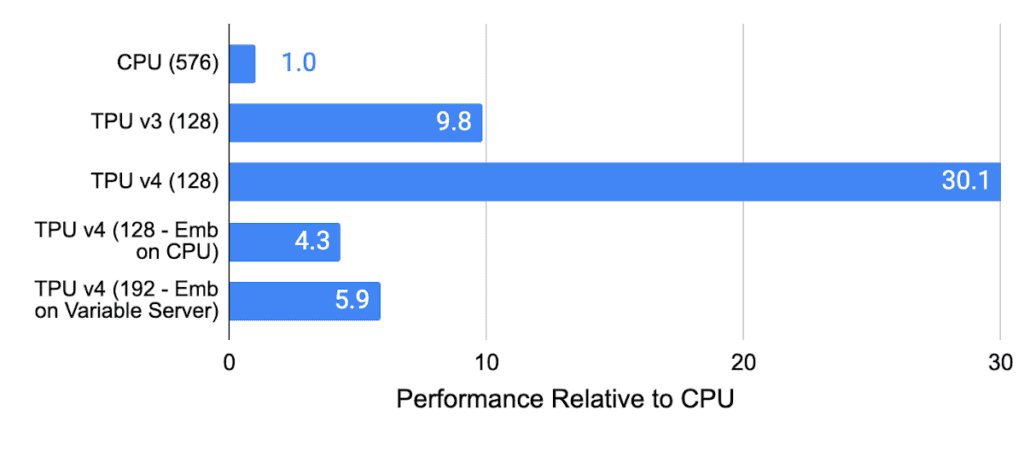
TPU v4 supercomputers have been crucial for training large language models such as LaMDA, MUM, and PaLM. These supercomputers are also the first to offer hardware support for embeddings, essential for Deep Learning Recommendation Models (DLRMs) used in advertising, search ranking, YouTube, and Google Play.
Since becoming available on Google Cloud, TPU v4 supercomputers have been utilized by leading AI teams worldwide for cutting-edge ML research and production workloads, including language models, recommender systems, and generative AI. AI institutions and startups like the Allen Institute for AI and Midjourney have praised the seamless scaling and high-speed mesh network offered by Cloud TPU v4.
Google will share more details about its TPU v4 research in a paper at the International Symposium on Computer Architecture and looks forward to discussing its findings with the community.