A Rigorous Evaluation Framework for Code Synthesis with Large Language Models
- Existing code evaluation datasets may not fully assess the functional correctness of code generated by Large Language Models (LLMs).
- EvalPlus is a benchmarking framework that uses both LLM-based and mutation-based input generators to rigorously evaluate the functional correctness of LLM-synthesized code.
- Extensive evaluation with HUMANEVAL+ shows significant amounts of previously undetected incorrect code, reducing pass@k by 15.1% on average.
The use of Large Language Models (LLMs) for code generation has gained significant attention, but questions remain about the accuracy and correctness of the code these models produce. Current code evaluation datasets may be limited in both quantity and quality, making it difficult to fully assess the functional correctness of LLM-generated code. To address this, researchers have proposed EvalPlus, a code synthesis benchmarking framework designed to rigorously evaluate LLM-synthesized code.
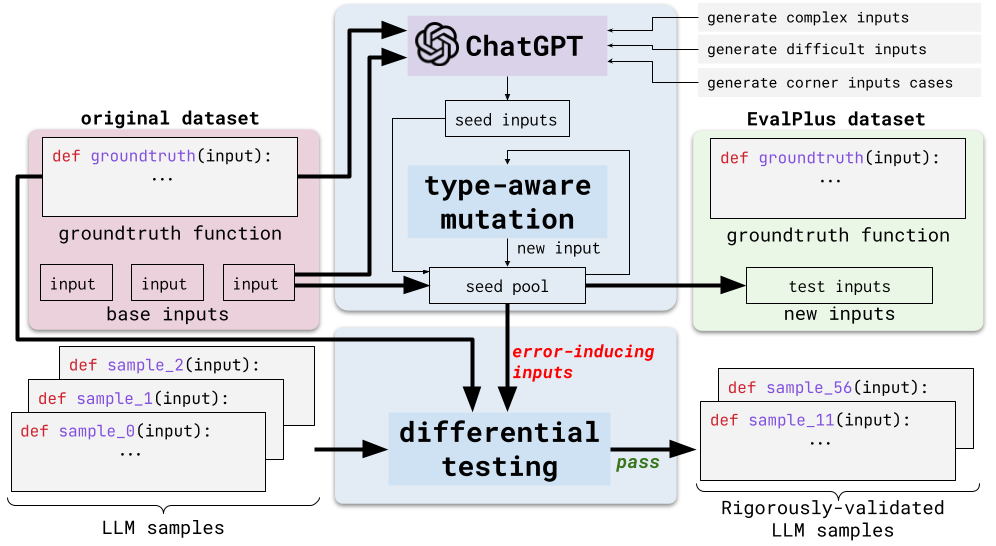
EvalPlus works by taking a base evaluation dataset and using automatic input generation to create and diversify a large number of new test inputs. This is achieved by combining LLM-based and mutation-based input generators. The framework is used to create HUMANEVAL+, an extended version of the popular HUMANEVAL benchmark, featuring 81 times more generated tests.
When evaluating 14 popular LLMs with HUMANEVAL+, the framework was able to identify significant amounts of previously undetected incorrect code, reducing the pass@k rate by an average of 15.1%. EvalPlus even discovered several incorrect ground-truth implementations in the original HUMANEVAL dataset. This demonstrates that current code synthesis evaluation results may not accurately reflect the true performance of LLMs and highlights the potential for automated test input generation to improve programming benchmarks.
Future work for EvalPlus includes extending the framework to other code benchmarks, exploring better test generation techniques, and leveraging test suite reduction techniques to maintain test effectiveness while reducing redundancy. The researchers also suggest integrating EvalPlus with formal verification tools to provide stronger evaluation guarantees when applicable. Additionally, the core test generation technique could be used to alert developers to potential flaws in AI-generated code snippets when engaged in AI pair programming, such as with Copilot.