From 720GB to 131GB: The Open-Source Revolution in Efficient, High-Performance AI Reasoning
- Radical Compression: DeepSeek-R1’s 671B parameter model shrank from 720GB to 131GB using dynamic 1.58-bit quantization—without sacrificing functionality.
- Smarter Quantization: Naive methods break models (think endless loops), but selectively applying 1.58-bit to MoE layers and 4-bit to others keeps performance intact.
- Open-Source Powerhouse: DeepSeek-R1 matches OpenAI’s O1 in math, code, and reasoning tasks, while distilled smaller models (1.5B to 70B) set new benchmarks.

The AI world is no stranger to the trade-off between model size and performance—until now. DeepSeek-R1’s leap to 1.58-bit quantization defies expectations, compressing its colossal 671B parameter model by 80% (720GB → 131GB) while retaining full functionality. Traditional quantization methods, which uniformly reduce bit depth across all layers, catastrophically fail here, producing gibberish like “Pygame’s Pygame’s Pygame’s…” or infinite “dark Colours” loops. The solution? Dynamic quantization: selectively applying higher precision (e.g., 4-bit) to critical layers while pushing most MoE (Mixture of Experts) layers to 1.58-bit.
MoE layers, which sparsely activate subsets of neural pathways (like GPT-4), proved uniquely resilient to ultra-low-bit compression. By contrast, dense layers—like the first three in DeepSeek-R1—demanded higher precision to preserve logic and coherence. The result? A model that fits into 160GB of VRAM(two H100 GPUs) and generates 140 tokens/second, democratizing access to cutting-edge AI for researchers and developers.
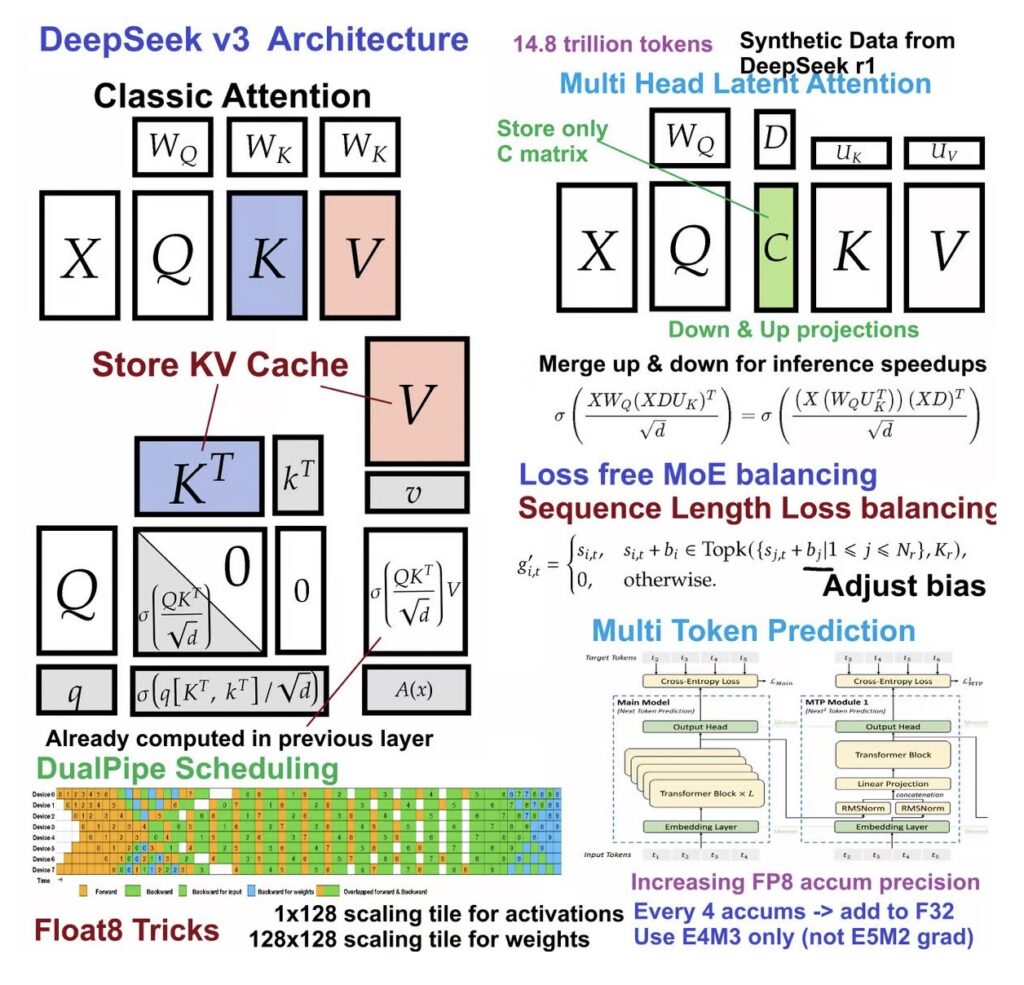
Beyond Size: The RL-First Pipeline Redefining Reasoning
DeepSeek-R1 isn’t just smaller—it’s smarter. Unlike conventional models that rely on supervised fine-tuning (SFT) to “teach” reasoning, DeepSeek-R1-Zero skips SFT entirely. Instead, it uses large-scale reinforcement learning (RL) to incentivize problem-solving behaviors like self-verification, reflection, and multi-step chain-of-thought (CoT) reasoning. This approach unlocked novel capabilities but came with quirks: repetitive outputs, language mixing, and poor readability.
Enter DeepSeek-R1, which introduces a “cold-start” phase: minimal SFT data primes the model before RL refinement. This hybrid pipeline balances creativity and coherence, achieving parity with OpenAI’s O1 model across benchmarks. The implications are profound: RL-first training validates that reasoning can emerge organically, bypassing the need for handcrafted SFT datasets—a paradigm shift for AI development.
Small Models, Giant Leaps
Bigger isn’t always better. By distilling DeepSeek-R1’s reasoning patterns into smaller models, the team created DeepSeek-R1-Distill-Qwen-32B, which outperforms OpenAI’s O1-mini. Even the 1.5B distilled variant excels, proving that knowledge transfer trumps training smaller models from scratch. Six open-source checkpoints—based on Llama and Qwen architectures—now empower the community to build efficient, high-performance AI without requiring H100 clusters.
The Technical Tightrope: Why 1.58 Bits Works (and 1.75 Doesn’t)
Quantizing DeepSeek-R1 was a high-wire act. While 1.58-bit dynamic quantization works, pushing further to 1.75-bit (149GB) caused total failure (e.g., rendering fully black screens in code outputs). Even 2.06-bit (175GB) performed worse than 1.58-bit, highlighting the non-linear relationship between bit depth and functionality. The team also identified a quirky bug: 1.58-bit models occasionally emit a single incorrect token, fixable by setting min_p = 0.1 during inference.
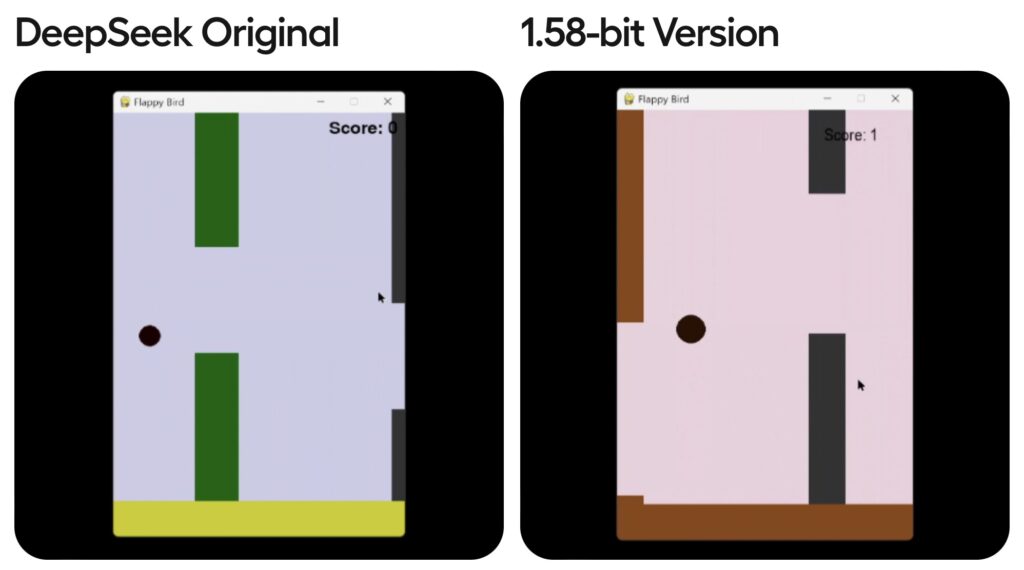
The Open-Source Edge
DeepSeek-R1’s release isn’t just a technical milestone—it’s a community catalyst. By open-sourcing everything from the 131GB quantized model to distilled variants, the team invites researchers to explore RL-driven reasoning, optimize quantization further, and push smaller models beyond current limits. Whether you’re running it on dual H100s or a CPU with 20GB RAM (slow but feasible), DeepSeek-R1 proves that open-source AI can rival proprietary giants—one carefully quantized bit at a time.