NVIDIA’s Latest Offering Enhances Data Retrieval for AI Application
- NVIDIA introduces NeMo Retriever NIM inference microservices to improve AI accuracy and efficiency.
- The microservices are integrated into platforms like Cohesity, DataStax, NetApp, and Snowflake.
- NeMo Retriever combines embedding and reranking models for superior data retrieval and relevance.
NVIDIA has launched a suite of NeMo Retriever NIM inference microservices, designed to significantly enhance the accuracy and throughput of large language models (LLMs) in AI applications. This innovation aims to help enterprises unlock the full value of their business data by enabling more precise and efficient data retrieval processes. The new microservices integrate seamlessly with platforms such as Cohesity, DataStax, NetApp, and Snowflake, making them production-ready and easy to deploy.
Enhancing AI with NeMo Retriever
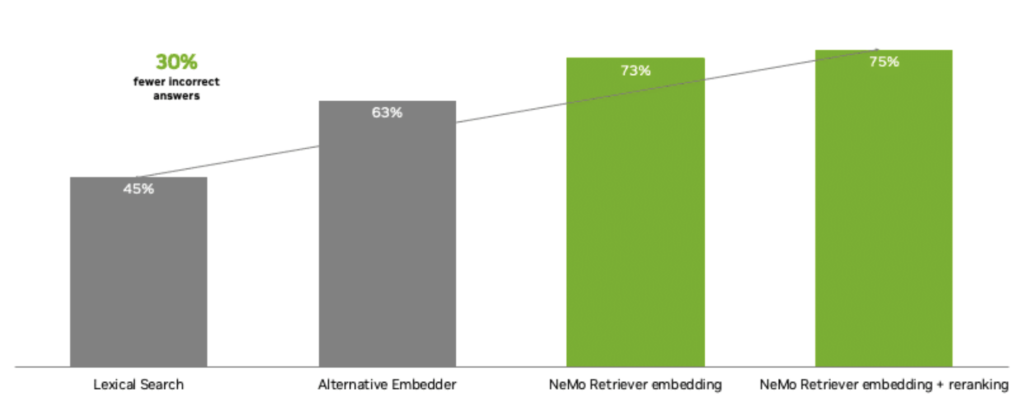
Generative AI applications rely heavily on the accuracy of the data they process. Without accurate data, these applications can produce misleading or useless results. NVIDIA’s NeMo Retriever addresses this challenge by providing a robust solution for retrieval-augmented generation (RAG). This approach allows AI models to fetch the most relevant proprietary data to generate knowledgeable responses, thereby enhancing the overall quality of AI outputs.
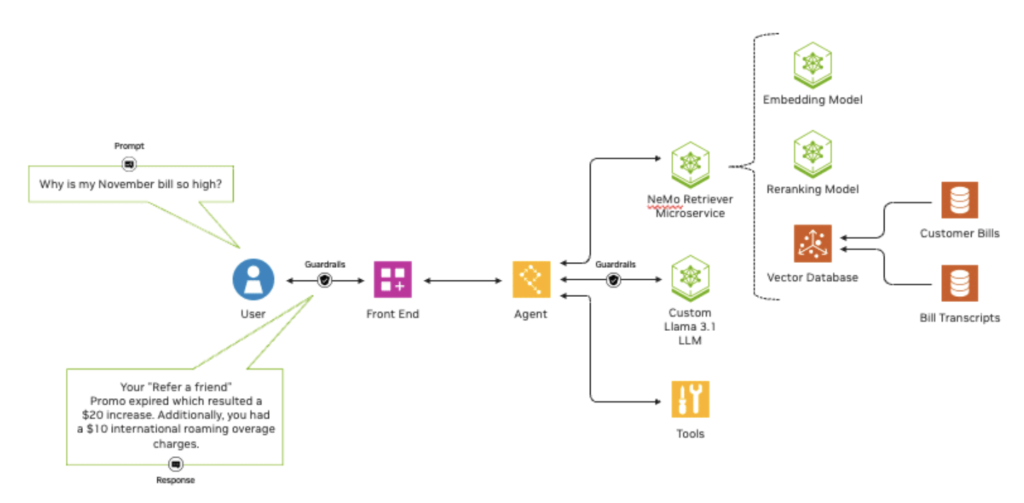
The NeMo Retriever microservices work by connecting custom models to diverse business data, enabling organizations to deliver highly accurate responses for AI applications. This capability is crucial for developing AI agents, customer service chatbots, security analysis tools, and systems that extract insights from complex datasets.
Key Features and Models
The NeMo Retriever NIM microservices include a range of models tailored for different aspects of data retrieval:
- NV-EmbedQA-E5-v5: Optimized for text question-answering retrieval.
- NV-EmbedQA-Mistral7B-v2: A multilingual model fine-tuned for high-accuracy text embedding.
- Snowflake-Arctic-Embed-L: An optimized community model.
- NV-RerankQA-Mistral4B-v3: Fine-tuned for text reranking to enhance question-answering accuracy.
These models are part of the NVIDIA API catalog and are designed to be transparent and reliable, offering both open and commercial options. Embedding models transform diverse data types into numerical vectors for efficient storage and retrieval, while reranking models score data based on its relevance to a given query. By using these models in tandem, NeMo Retriever ensures that AI applications can provide the most accurate and contextually relevant information.
Real-World Applications and Impact
NeMo Retriever’s capabilities extend across a wide range of AI applications. For instance, developers can create intelligent chatbots that offer accurate, context-aware responses, or build tools that analyze large datasets to identify security vulnerabilities. The microservices also support AI-enabled retail shopping advisors, enhancing customer experiences by providing personalized recommendations.
Several NVIDIA data platform partners are already integrating NeMo Retriever into their services. DataStax uses the embedding microservices in its Astra DB and Hyper-Converged platforms to bring generative AI-enhanced RAG capabilities to market faster. Cohesity plans to integrate these microservices with its AI product, Cohesity Gaia, to empower customers with insightful, transformative AI applications. Similarly, Kinetica is leveraging NeMo Retriever to develop LLM agents that can quickly respond to network outages or breaches.
NetApp’s collaboration with NVIDIA aims to connect NeMo Retriever microservices to vast amounts of data on its intelligent data infrastructure. This integration allows NetApp ONTAP customers to access proprietary business insights without compromising data security or privacy.
Integration and Flexibility
NVIDIA’s NIM microservices offer a modular approach to building AI applications, providing developers with the flexibility to integrate them with other NVIDIA models, community models, or custom models. These microservices can be deployed in the cloud, on-premises, or in hybrid environments, supporting various accelerated infrastructures from providers like Amazon Web Services, Google Cloud, Microsoft Azure, and Oracle Cloud Infrastructure.
NVIDIA Developer Program members will soon have access to NIM microservices for free, allowing them to conduct research, development, and testing on their preferred infrastructure. This accessibility will likely spur further innovation and adoption of NVIDIA’s AI technologies.
NVIDIA’s NeMo Retriever NIM inference microservices represent a significant advancement in the field of AI, offering enhanced accuracy and efficiency for a wide range of applications. By combining powerful embedding and reranking models, these microservices enable enterprises to harness the full potential of their data, providing highly accurate and relevant AI-driven insights. As these technologies continue to integrate into various platforms and industries, they promise to drive the next wave of innovation in AI data retrieval and application development.