Exploring the Hidden Flaws in UQ Evaluation and the Promise of LM-as-a-Judge
- Uncertainty Quantification (UQ) in Language Models (LMs) is vital for safety and reliability, but current evaluation methods are often distorted by biases in correctness functions, particularly due to response length.
- A comprehensive study across multiple datasets, models, and UQ methods reveals that lexical and embedding-based metrics inflate performance results, while LM-as-a-judge approaches offer a less biased alternative.
- Despite its promise, LM-as-a-judge has limitations, including computational costs and potential correlations, highlighting the need for further research into unbiased UQ evaluation.
Uncertainty Quantification (UQ) in Language Models (LMs) stands as a cornerstone for ensuring the safety and reliability of AI systems. As these models are increasingly deployed in critical applications, from healthcare diagnostics to legal document analysis, understanding and quantifying their uncertainty becomes paramount. However, the methods we use to evaluate UQ are not as foolproof as they seem. A deep dive into the evaluation process reveals a troubling flaw: the metrics and correctness functions we rely on to assess UQ performance are often biased, particularly by the length of the model’s responses. This article explores the intricacies of UQ evaluation, uncovers the biases that threaten its integrity, and proposes a potential solution that could reshape how we measure uncertainty in LMs.
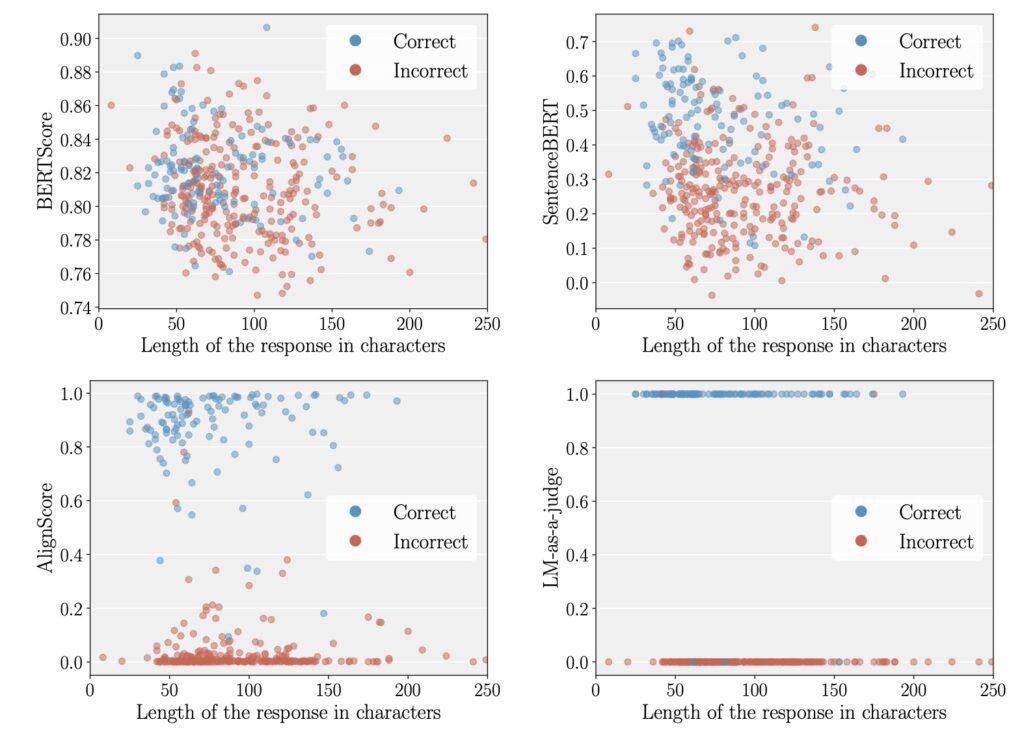
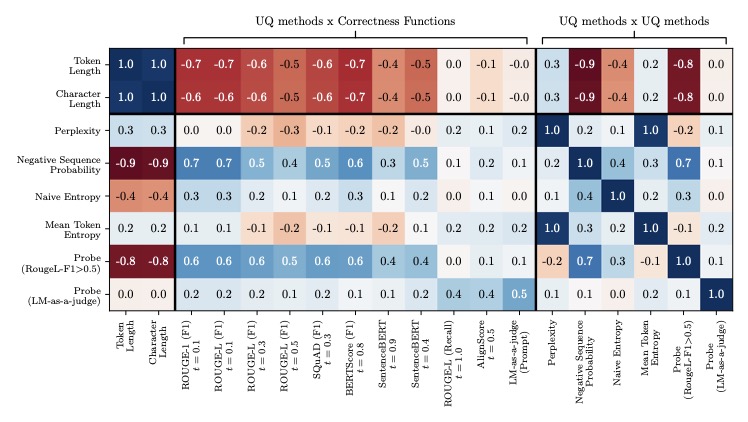
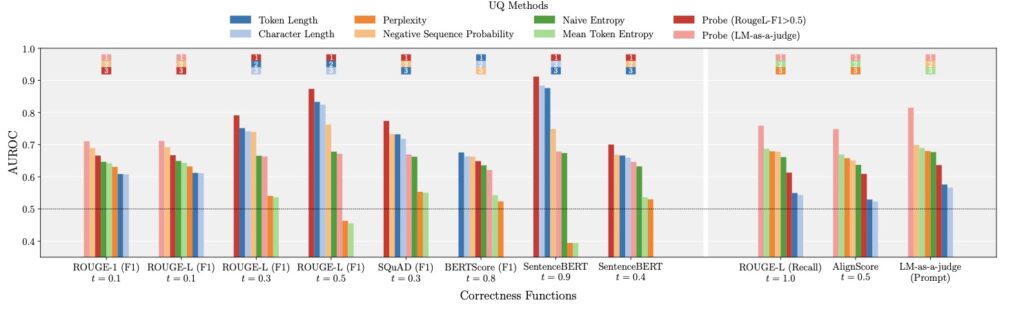
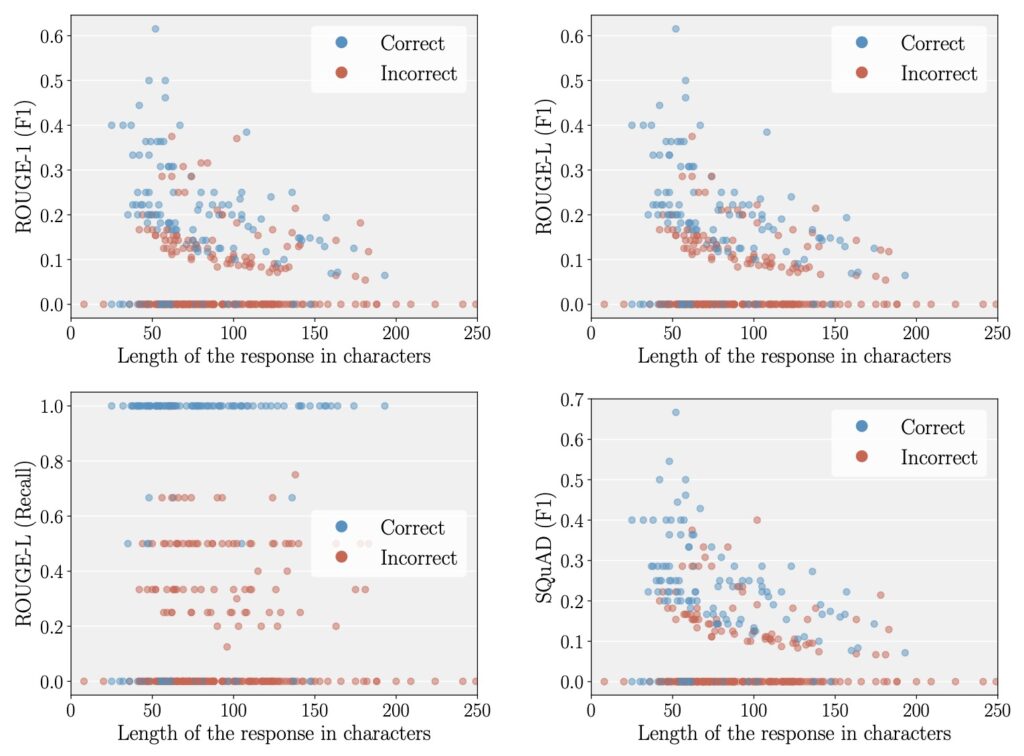
At the heart of UQ evaluation lies the correctness function—a mechanism designed to determine whether a model’s output is accurate. Common correctness functions range from lexical-based metrics like ROUGE-L to embedding-based approaches and even advanced methods where another language model acts as a judge (LM-as-a-judge). These functions are paired with performance metrics like AUROC to gauge how well UQ methods, such as negative sequence probabilities, correlate with task correctness. However, our analysis across four datasets, four models, and six UQ methods reveals a pervasive issue: many correctness functions, especially lexical and embedding-based ones, exhibit a length bias. This means that longer responses are often scored more favorably, regardless of their actual quality, which in turn inflates the perceived performance of certain UQ methods that are similarly biased toward length. The result is a distorted picture of a model’s uncertainty quantification capabilities, undermining the trustworthiness of benchmark results.
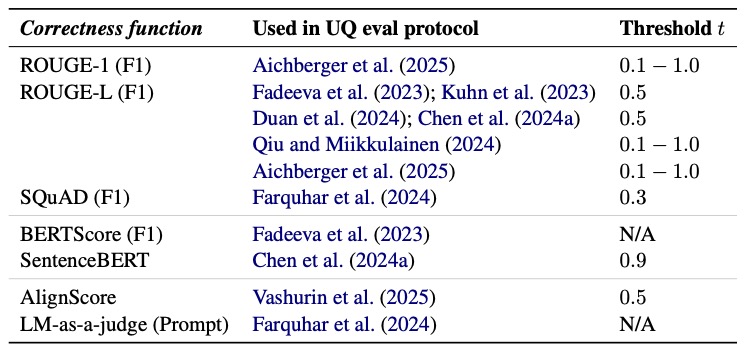
The implications of this bias are far-reaching. When UQ evaluations are skewed by response length, we risk overestimating a model’s reliability, potentially deploying systems that fail to accurately signal uncertainty in real-world scenarios. Imagine a medical chatbot that generates lengthy but incorrect diagnoses, yet scores high on UQ metrics due to length bias—such a system could have catastrophic consequences. Our study meticulously evaluated seven correctness functions and found that lexical and embedding-based metrics are particularly prone to these spurious interactions. For instance, metrics like ROUGE-L, which measure overlap in text, often favor longer outputs simply because they have more opportunities for matching tokens, not because they are inherently more correct. This length dependency creates a feedback loop with UQ methods that also prioritize longer responses, leading to artificially high performance scores.
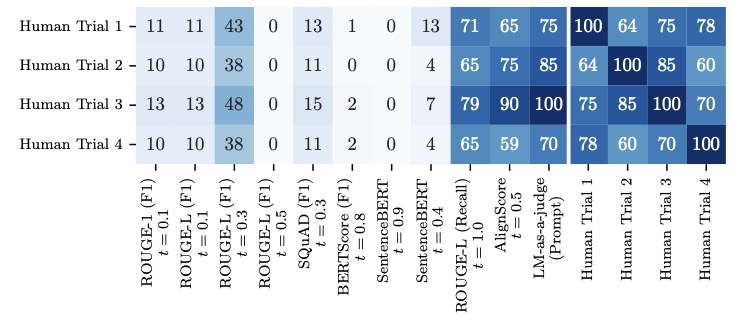
Amidst these challenges, one approach stands out as a beacon of hope: the LM-as-a-judge method. Unlike traditional metrics, LM-as-a-judge uses another language model to assess the correctness of outputs, often providing a more nuanced evaluation that is less influenced by response length. Our analysis indicates that this method is among the least length-biased options, making it a promising candidate for mitigating the distortions seen in other correctness functions. By leveraging the contextual understanding of a judging LM, this approach can better discern the quality of an answer, whether it’s concise or verbose. However, it’s not a silver bullet. The reliability of LM-as-a-judge depends heavily on the choice of the judging model and the formulation of prompts used to elicit judgments. If the same LM is used for both judging and as part of the UQ method, there’s a risk of correlated errors that could again inflate performance metrics, though such errors are relatively infrequent.
The LM-as-a-judge approach comes with practical limitations. Its computational overhead is significant compared to traditional correctness functions, posing challenges for resource-constrained environments. Additionally, while our study focused on question-answering (QA) tasks—chosen for their well-defined nature and prominence in UQ literature—the generalizability of LM-as-a-judge to other tasks like machine translation or summarization remains uncertain. Previous research suggests that length biases in correctness functions are not unique to QA, implying that similar issues may plague UQ evaluations in more open-ended domains. Yet, without rigorous testing against human annotators across diverse tasks and datasets, we cannot be certain that the same judging model and prompts will perform consistently. This underscores the need for careful validation before widespread adoption of LM-as-a-judge in UQ benchmarking.
Beyond length bias, our research also hints at other latent variables that may subtly influence UQ methods and correctness functions. While response length emerged as a primary confounding factor, additional biases—potentially related to dataset characteristics or model-specific tendencies—could further complicate evaluations. Unraveling these hidden influences is crucial for refining UQ protocols and ensuring that assessments of model uncertainty are both accurate and reliable. The path forward requires not only adopting less biased correctness functions like LM-as-a-judge but also deepening our understanding of the broader ecosystem of biases that affect UQ benchmarking.
The evaluation of Uncertainty Quantification in Language Models is at a critical juncture. While the field has made strides in recognizing the importance of UQ for safe and reliable AI, the tools we use to measure it are flawed, often skewed by biases like response length that compromise the integrity of results. Our comprehensive analysis across multiple dimensions—datasets, models, and methods—exposes these flaws and points to LM-as-a-judge as a potential solution, albeit one with its own set of challenges. As we move forward, the AI community must prioritize the development of unbiased evaluation frameworks, rigorously test emerging methods against human judgment, and remain vigilant for other hidden biases. Only then can we ensure that the uncertainty quantified in our language models reflects reality, paving the way for AI systems that are not just powerful, but truly trustworthy.