How a new open-source breakthrough is bridging the gap between passive video generation and interactive reality.
- The Shift to Simulation: LingBot-World marks a transition from AI that merely “dreams” video pixels to a model that understands physics, causality, and object permanence.
- High-Performance Interactivity: The model offers high-fidelity visuals across diverse styles, minute-long “memory” consistency, and real-time responsiveness with sub-1-second latency.
- Open-Source Access: By releasing the code and model publicly, LingBot-World aims to democratize advanced world modeling for gaming, robotics, and content creation.

The pursuit of artificial intelligence capable of truly understanding and simulating the physical world has long been considered a “holy grail” in computer vision and machine learning. We are currently witnessing a massive paradigm shift in generative models. The industry is transitioning from static “text-to-video” generation to the far more ambitious goal of “text-to-world” simulation.

While state-of-the-art video generation models have achieved remarkable fidelity in rendering short, visually coherent clips, they fundamentally remain “dreamers” rather than “simulators.” They hallucinate pixel transitions based on statistical correlations but often lack a grounded understanding of the underlying laws—such as causality, object permanence, and the consequences of interaction. To bridge this gap, we must move beyond generating passive footage and towards building world models capable of synthesizing persistent, interactive, and logically consistent environments.
Introducing LingBot-World
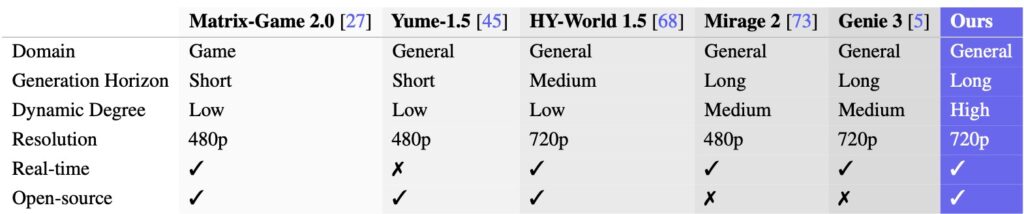
We present LingBot-World, an open-sourced world simulator stemming from video generation. Positioned as a top-tier world model, it is designed to narrow the divide between open-source and proprietary closed-source technologies.

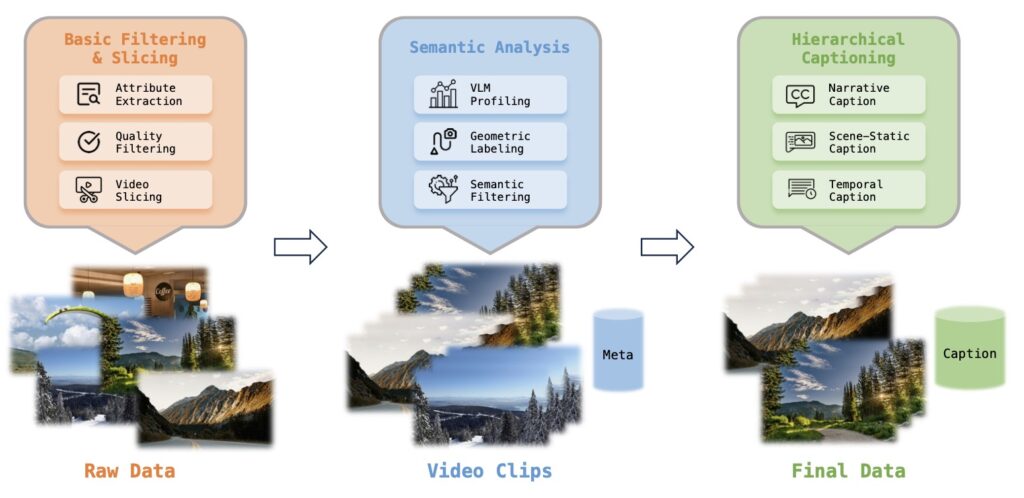
LingBot-World is not just a video generator; it is a framework for interactive world modeling. At its core, the LingBot-World-Base delivers high-fidelity, controllable, and logically consistent simulations. Powered by a proprietary Scalable Data Engine, the system treats game engines as infinite data generators. By learning physics and causality from massive-scale gaming environments, the model unifies the logic of physical and game worlds, enabling robust generalization from synthetic data to real-world scenarios.
Three Pillars of Performance
LingBot-World distinguishes itself through three specific features that set a new standard for open-source models:
- High Fidelity and Robust Dynamics: It maintains exceptional visual quality across a broad spectrum of environments. whether the context is photorealism, scientific simulation, or stylized cartoon aesthetics.
- Long-Term “Memory”: The model enables a minute-level horizon while preserving contextual consistency over time. This ability to maintain structural integrity and narrative logic over longer trajectories solves a common issue where AI videos lose coherence after a few seconds.
- Real-Time Interactivity: Leveraging LingBot-World-Fast, the system achieves a latency of under 1 second when producing 16 frames per second. This allows for real-time, closed-loop control, making the video output “playable.”

From Passive Viewing to Active Control
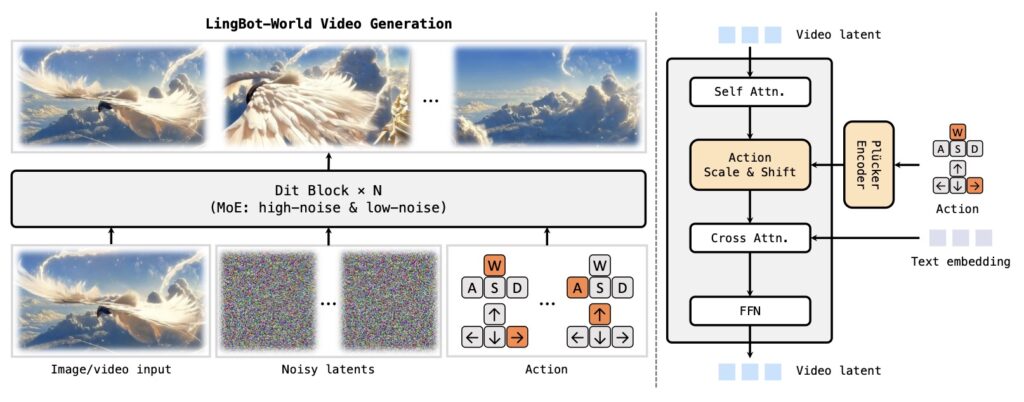
The model moves beyond random hallucinations to support fine-grained, action-conditioned generation. It precisely responds to user commands to render high-quality, physically plausible dynamic scenes. As the world model scales, we have observed the emergence of sophisticated behaviors that demonstrate a genuine understanding of spatial logic and physical constraints.

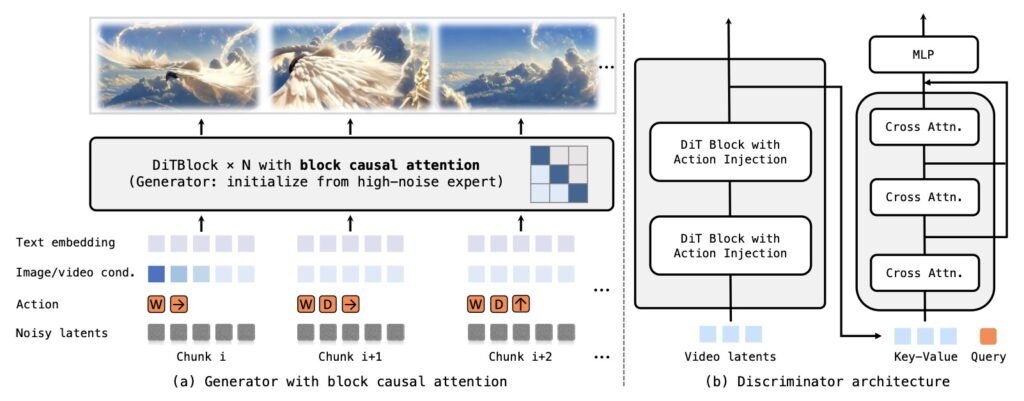
Our contributions cover the entire pipeline, starting with a robust data engine that ensures high-quality training data. On the modeling front, we utilize a causal transformer architecture optimized for accurate action-control and employ real-time distillation to enable efficient inference. These advancements culminate in diverse applications, demonstrating the model’s capability in executing agentic actions, performing consistent world editing, and supporting 3D environment reconstruction.
The Road Ahead: Challenges and Frontiers
Despite these significant advancements, achieving a fully immersive and persistent virtual world remains a complex challenge. We believe in transparency regarding the current limitations of LingBot-World to foster community development:
- Computational Intensity: Running the model currently requires enterprise-grade GPUs, making it inaccessible to average consumer hardware.
- Memory Stability: The model’s memory is an emergent ability derived from the context window rather than an explicit storage module. This can lead to “drifting,” where the scene gradually loses its original structure during extended gameplay.
- Interaction Precision: While navigation is robust, fine-grained control remains difficult. Interacting with specific target objects (e.g., picking up a specific cup on a cluttered table) is challenging due to a lack of precise object-level grounding.
- Single-Agent Limits: The current framework supports only single-agent perspectives and does not yet account for complex multi-agent interactions.
By providing public access to the code and model, we aim to empower the community to tackle these challenges. We believe LingBot-World will serve as a foundational tool for practical applications across content creation, gaming, and robot learning, ushering in a new era where AI doesn’t just watch the world, but learns to simulate it.