How a new hybrid architecture bridges the gap between deep semantic understanding and high-fidelity visuals
- A “Best of Both Worlds” Architecture: GLM-Image introduces an industrial-grade hybrid design, combining a 9-billion parameter auto-regressive model (for understanding) with a 7-billion parameter diffusion decoder (for visual fidelity).
- Solving the Hard Problems: By decoupling semantic understanding from detail generation, the model excels in areas where standard diffusion models struggle, specifically text rendering, complex instruction following, and knowledge-intensive scenarios.
- Advanced Training Techniques: The model utilizes Semantic-VQ tokenization for better convergence and a unique “disentangled” reinforcement learning strategy (GRPO) to separately optimize aesthetics and fine-grained details like hands and text.
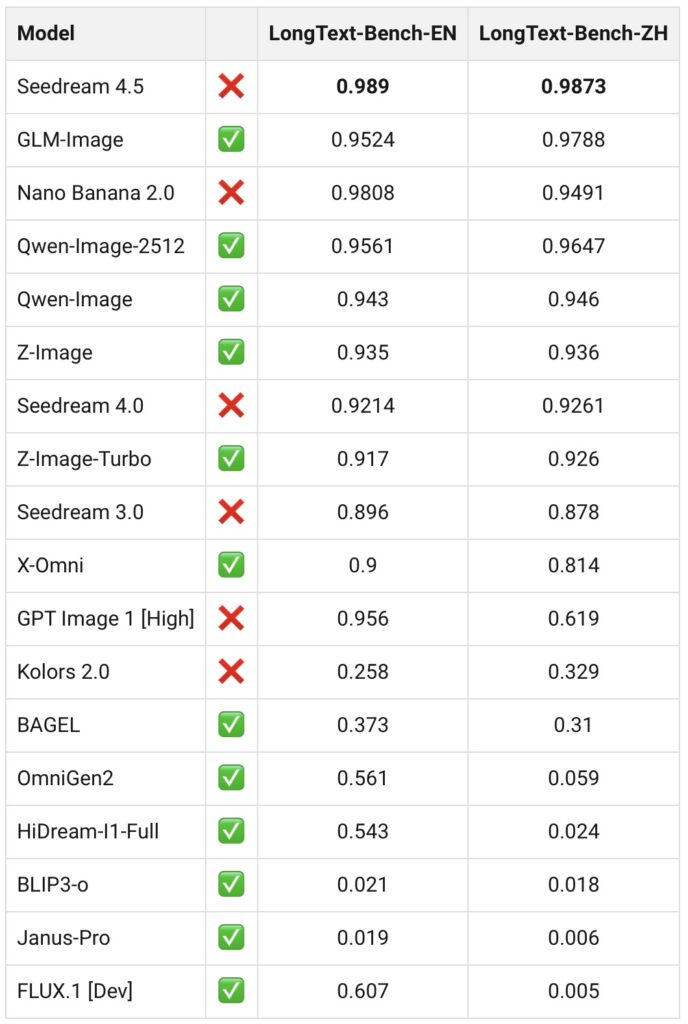
The landscape of AI image generation has long been dominated by diffusion models. While these models offer training stability and generalization, they often hit a ceiling when faced with complex instructions or tasks requiring deep knowledge. Enter GLM-Image, the first open-source, industrial-grade discrete auto-regressive image generation model.
GLM-Image represents a paradigm shift by adopting a hybrid architecture. It marries the logical strengths of an auto-regressive module with the artistic precision of a diffusion decoder. While it matches mainstream latent diffusion models in general image quality, it pulls ahead significantly in “knowledge-intensive” generation—tasks that require precise semantic understanding and complex information expression—while maintaining high-fidelity visuals. Beyond simple text-to-image tasks, it is a powerhouse for image editing, style transfer, identity preservation, and multi-subject consistency.

The Architecture: Brains Meets Beauty
The core philosophy behind GLM-Image is “decoupling.” The team recognized that understanding a complex prompt and rendering pixels are two different challenges.
The model is split into two distinct parts:
- The Auto-Regressive Generator (The Brain): Initialized from the GLM-4-9B-0414 language model (9 billion parameters), this component is responsible for processing the text and generating “tokens” that represent the low-frequency semantic layout of the image. It understands what should be in the image.
- The Diffusion Decoder (The Artist): Based on CogView4 technology, this 7-billion parameter single-stream DiT (Diffusion Transformer) structure takes those semantic tokens and refines them into high-frequency details. It handles the textures, lighting, and fine lines.
Visual Token Selection: Why “Semantic-VQ” Matters
In visual auto-regressive models, how you translate an image into “words” (tokens) is critical. Previous models used various methods, ranging from VQVAE (high information, low semantic relevance) to 1D vectors (high semantics, low information).
GLM-Image chooses a middle path that offers the best convergence: Semantic-VQ.
Research by the team showed that tokens derived from Semantic-VQ offer superior convergence properties for visual generation compared to standard VQVAE (training loss of ~3 vs ~7). While 1D vectors (used in models like DALLE2 or FLUX.1 Redux) are good for subject consistency, they lack the information completeness required for a primary generator. By using the tokenizer scheme from XOmni, GLM-Image ensures strong semantic correlation during modeling, which is then decoded by the diffusion system.

Intelligent Pre-training and Progressive Generation
The training process for GLM-Image is as innovative as its architecture. The model freezes the text word embedding layer but adds a vision word embedding layer. To handle the complex interleaving of text and images, it implements MRoPE(Multidimensional Rotary Positional Embeddings).
The training moves through multiple resolution stages, starting at 256px and moving up to mixed resolutions spanning 512px to 1024px. The tokenizer compresses images with a 16x ratio, meaning the model handles sequence lengths ranging from 256 to 4096 tokens.
The “Progressive Generation” Breakthrough During high-resolution training, the team noticed a drop in controllability. To fix this, they adopted a progressive generation strategy. The model first generates a small batch of tokens (approx. 256) based on a down-sampled version of the image. These preliminary tokens determine the global layout. By increasing the training weight of these initial tokens, the model ensures the final high-resolution output adheres strictly to the intended composition.
The Diffusion Decoder: Precision and Efficiency
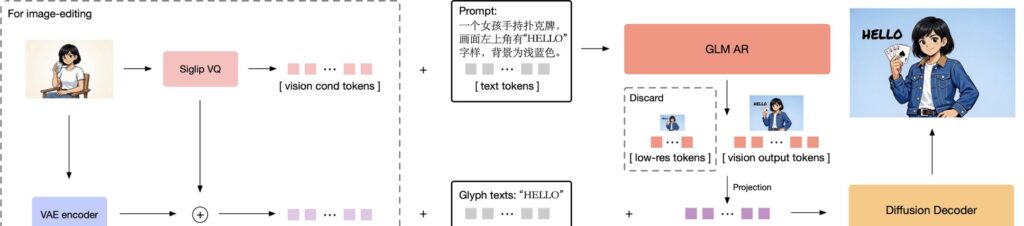
The diffusion decoder in GLM-Image is designed for efficiency. Because the incoming Semantic-VQ tokens already carry rich semantic data, the decoder does not need a text prompt input. This eliminates the need for a massive text encoder in the decoding stage, saving significant memory and compute.
To address the common pain point of generating text within images (specifically complex characters like Chinese), the decoder integrates a lightweight Glyph-byT5 model. This provides character-level encoding for rendered text regions, ensuring that when you ask for specific words in an image, they are spelled correctly.
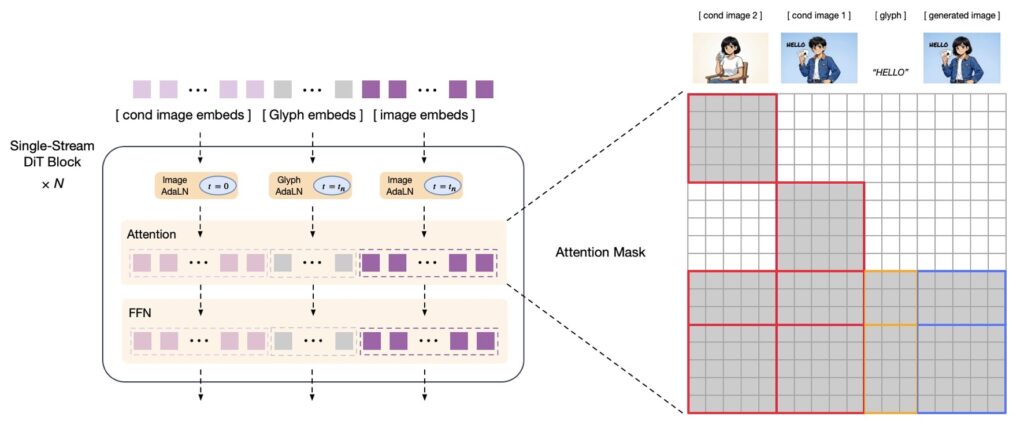
For image editing, the model utilizes a block-causal attention mechanism (similar to ControlNet-Reference-Only). This allows the model to reference original images to preserve high-frequency details without the heavy computational overhead of full attention mechanisms used in competitors like Qwen-Image-Edit.
Disentangled Post-Training with GRPO
The final polish of GLM-Image comes from a sophisticated post-training stage using GRPO (Group Relative Policy Optimization). Uniquely, the model uses a “disentangled” reward system:
- The Auto-Regressive Module is optimized for low-frequency rewards. It is guided by HPSv3 (aesthetic scoring), VLM (semantic correctness), and OCR to ensure it follows instructions and understands the prompt’s intent.
- The Diffusion Decoder is optimized for high-frequency rewards. It uses Flow-GRPO to focus on LPIPS (texture and detail similarity), OCR (text precision), and a dedicated hand-scoring model to ensure anatomical correctness.
By optimizing these two parts separately, GLM-Image achieves a new standard where artistic aesthetics meet industrial precision.