Unlocking Superior Image Quality and Alignment in Flow-Matching Models
- Overcoming GRPO’s Core Flaws: Traditional Group Relative Policy Optimization (GRPO) excels in flow-matching-based text-to-image (T2I) generation but struggles with inaccurate advantage attribution and ignoring temporal dynamics—issues that Chunk-GRPO elegantly resolves by shifting focus from individual steps to cohesive chunks.
- The Power of Chunk-Level Optimization: By grouping consecutive timesteps into “chunks” that capture the natural flow of generation, this innovative approach boosts both preference alignment and overall image quality, as validated through extensive experiments.
- Future Horizons and Enhancements: While delivering consistent gains over step-level methods, Chunk-GRPO opens doors to advanced techniques like heterogeneous rewards and dynamic chunking, promising even greater advancements in AI-driven creativity.
In the rapidly evolving world of artificial intelligence, text-to-image (T2I) generation stands as one of the most captivating frontiers, turning simple prompts into vivid visuals with remarkable speed and realism. At the heart of many cutting-edge models lies flow-matching, a technique that guides the diffusion process from noise to coherent images. Yet, optimizing these models for user preferences—ensuring outputs align with aesthetic ideals or specific instructions—remains a challenge. Enter Group Relative Policy Optimization (GRPO), a promising method that’s gained traction for fine-tuning T2I systems. However, as researchers delve deeper, they’ve uncovered GRPO’s Achilles’ heels: inaccurate advantage attribution, where rewards aren’t properly linked to generative actions, and a glaring oversight of the temporal dynamics that unfold during image creation. These limitations can lead to suboptimal results, like misaligned compositions or lackluster details, frustrating creators who rely on AI for everything from digital art to marketing visuals.
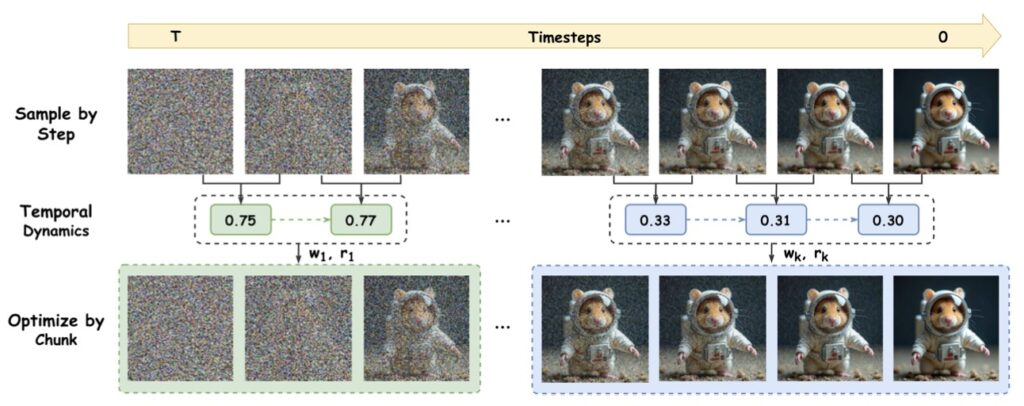
This is where a paradigm shift becomes not just innovative, but essential. Imagine moving beyond the granular, step-by-step tweaks that bog down traditional GRPO. Instead, what if we could bundle those steps into meaningful “chunks”—coherent blocks that respect the intrinsic rhythm of flow matching? This is the core insight behind Chunk-GRPO, the pioneering chunk-level GRPO-based approach for T2I generation. Developed as a direct response to GRPO’s shortcomings, Chunk-GRPO reimagines optimization by grouping consecutive timesteps into these chunks, allowing the model to process and refine larger segments of the generation process holistically. The result? A more intuitive handling of how images evolve over time, from the noisy beginnings to the polished finale, leading to outputs that feel more natural and aligned with human intent.
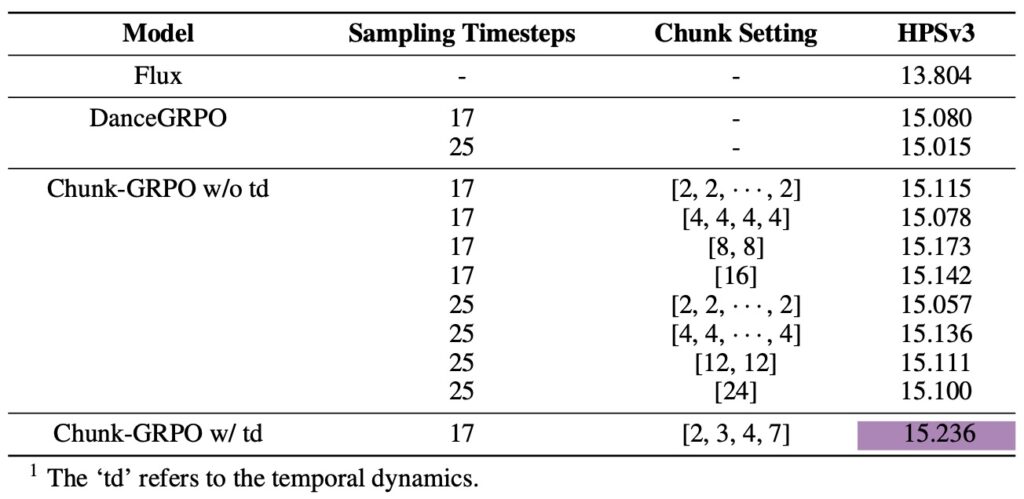
To understand Chunk-GRPO’s brilliance, let’s break down its mechanics. In standard flow-matching T2I pipelines, generation proceeds in discrete steps, each adjusting the image state incrementally. GRPO optimizes policies at this step level, but this fine-grained view often misses the bigger picture: the temporal dependencies where early decisions ripple through later ones. Chunk-GRPO flips the script by defining chunks as sequences of these steps, capturing the flow’s dynamic progression. For instance, an initial chunk might handle the broad structural formation in high-noise phases, while later ones refine textures and details in lower-noise stages. By optimizing at this chunk level, the method ensures advantages—those critical rewards signaling “good” versus “bad” outputs—are attributed more accurately across related actions. This isn’t just theoretical; it’s a practical leap that addresses GRPO’s neglect of temporal flow, making the entire generation process more efficient and effective.

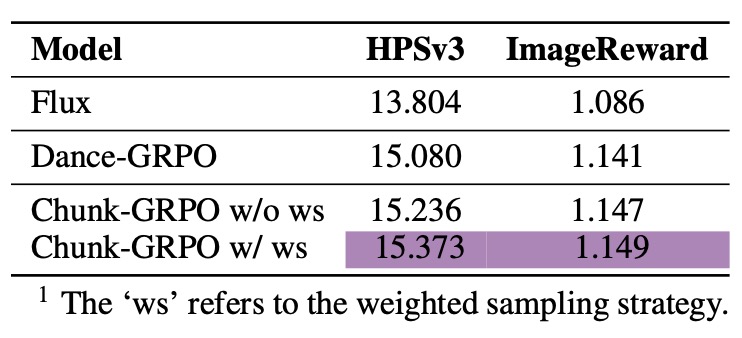
Building on this foundation, the creators of Chunk-GRPO introduce an optional weighted sampling strategy that elevates performance even further. During training, this technique prioritizes chunks based on their potential impact, drawing from a pool of samples with weights that reflect noise levels or reward variations. It’s like giving the AI a smarter roadmap: instead of treating every step equally, it focuses computational power where it matters most, accelerating convergence and enhancing fine details. Extensive experiments across benchmarks have borne this out, with Chunk-GRPO consistently outperforming step-level GRPO in key metrics. Preference alignment—how well images match subjective ideals like composition or style—sees marked improvements, while objective image quality scores, such as FID (Fréchet Inception Distance), drop to reveal sharper, more coherent results. In real-world tests, this translates to T2I models that not only generate faster but also produce visuals that resonate more deeply with users, from artists sketching concepts to designers prototyping campaigns.
From a broader perspective, Chunk-GRPO’s emergence signals a maturing field where AI optimization is evolving beyond brute-force computation toward biologically inspired efficiency. Flow-matching itself draws from physical principles, mimicking how particles flow from disorder to order, and chunking echoes how human cognition processes information in bursts rather than atoms. This approach could ripple across generative AI, influencing not just T2I but video synthesis, 3D modeling, and even language generation, where temporal coherence is king. Consider the implications for industries: in advertising, Chunk-GRPO-powered tools could churn out hyper-personalized visuals that nail brand aesthetics on the first try, reducing iteration cycles. For education, it might democratize art creation, allowing students to visualize historical scenes or scientific concepts with unprecedented fidelity. And in entertainment, imagine game developers leveraging chunk-optimized models to generate dynamic worlds that adapt seamlessly to player inputs.

Yet, no breakthrough is without its horizons to chase. Despite Chunk-GRPO’s strong performance, opportunities for refinement abound. One intriguing avenue is integrating heterogeneous rewards across chunks—for example, deploying specialized reward models tailored to high-noise regions (where structure emerges) versus low-noise ones (where finesse shines). This could unlock nuanced control, letting users fine-tune aspects like vibrancy or realism independently. Another limitation lies in the fixed chunk segmentation used throughout training; it’s effective but static. Future iterations might incorporate self-adaptive or dynamic chunking, where boundaries shift in response to real-time training signals, much like how a conductor adjusts tempo mid-performance. These enhancements could push Chunk-GRPO toward even greater versatility, potentially integrating with multimodal AI systems that blend text, image, and audio.

As we stand on the cusp of this chunk-level revolution, Chunk-GRPO exemplifies how targeted innovations can propel AI forward. By honoring the temporal dance of generation, it doesn’t just fix GRPO’s flaws—it redefines what’s possible in T2I, paving the way for more intuitive, high-fidelity creativity. For researchers and practitioners alike, this method isn’t merely an upgrade; it’s a blueprint for the next era of generative intelligence, where every chunk of progress brings us closer to AI that truly understands the art of creation.