New dataset boosts medical capabilities of large language models
- PubMedVision dataset refines medical image-text pairs to enhance multimodal large language models (MLLMs).
- HuatuoGPT-Vision, trained on PubMedVision, outperforms open-source models in medical scenarios.
- Dataset addresses data noise and quality issues, showing significant improvements on medical benchmarks.
In a significant leap for medical AI, researchers have developed HuatuoGPT-Vision, a multimodal large language model (MLLM) specifically enhanced with medical visual knowledge. Leveraging the new PubMedVision dataset, this model aims to address the limitations faced by existing MLLMs, such as GPT-4V, in medical applications.
Refining Medical Data
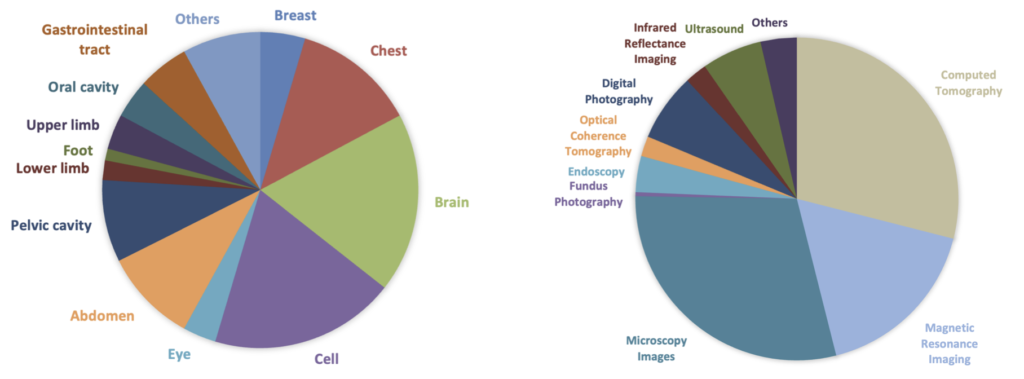
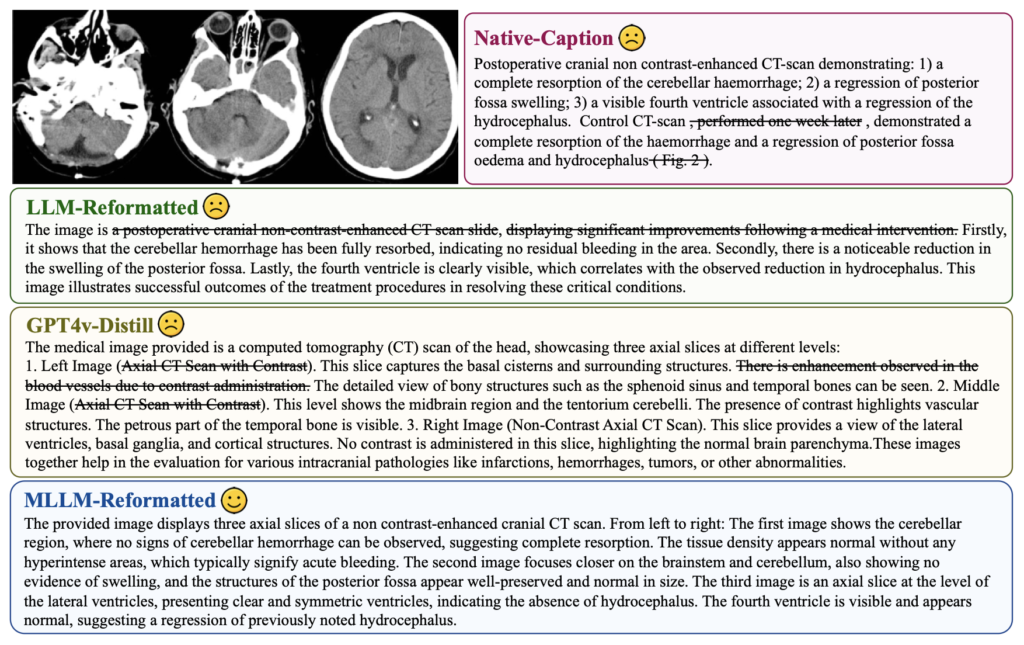
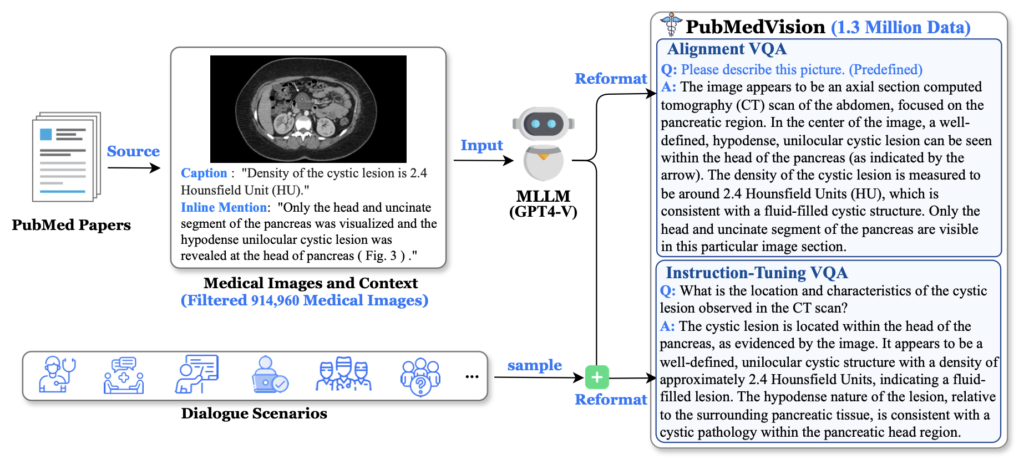
The journey to creating HuatuoGPT-Vision began with the recognition of a critical challenge: the scarcity and low quality of medical vision-text data. While existing approaches utilize large-scale datasets from PubMed, they often fall short due to inherent data noise and quality issues. To overcome this, researchers meticulously refined medical image-text pairs from PubMed, employing MLLMs like GPT-4V to denoise and reformat the data. This process led to the creation of the PubMedVision dataset, comprising 1.3 million high-quality medical visual question-answer (VQA) samples.
Training HuatuoGPT-Vision
Using the PubMedVision dataset, researchers trained HuatuoGPT-Vision, a robust 34-billion parameter model designed for medical multimodal scenarios. The new model demonstrated superior performance on various medical benchmarks, including the MMMU Health & Medicine track, showcasing its enhanced capabilities in understanding and generating medical visual content.
Addressing Challenges
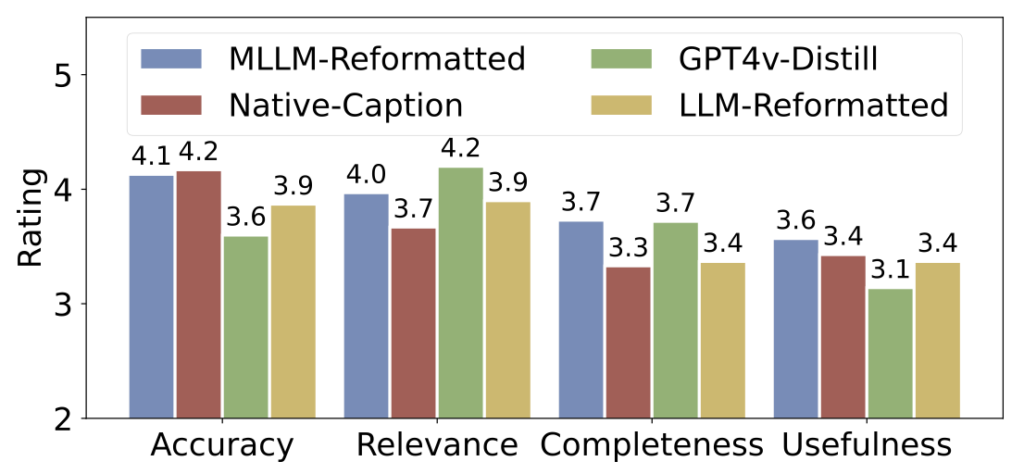
The development of PubMedVision was a meticulous process aimed at tackling the data noise that previously plagued models trained on PubMed datasets. By using advanced reformatting methods powered by MLLMs, the researchers significantly improved the quality of the data. This high-quality dataset not only boosts the performance of HuatuoGPT-Vision but also sets a new standard for future medical MLLMs.
Impact and Future Directions
The validation of PubMedVision involved rigorous manual checks by medical experts, ensuring its reliability and superiority over other data construction methods. The enhanced dataset and the resulting HuatuoGPT-Vision model mark a significant step forward in the application of AI in the medical field. The research underscores the potential of leveraging refined medical data to improve the multimodal capabilities of large language models.


Moving forward, the team hopes that PubMedVision will inspire further advancements in medical AI, enabling the development of even more sophisticated and capable models. The successful integration of high-quality medical visual knowledge into MLLMs like HuatuoGPT-Vision could pave the way for more accurate and efficient medical diagnostics, research, and education, ultimately benefiting healthcare providers and patients alike.

