StdGEN offers an advanced pipeline for high-quality, semantically decomposed 3D characters ready for gaming, VR, and film production.
- Fast, High-Quality 3D Generation: StdGEN creates intricately detailed 3D characters from a single image in just three minutes, far outpacing traditional methods.
- Semantic Decomposition for Flexibility: The model separates character components like body, clothes, and hair, enabling customization and easy animation.
- State-of-the-Art Technology: Powered by a Semantic-aware Large Reconstruction Model (S-LRM), StdGEN achieves superior geometry, texture, and decomposability compared to existing methods.

Creating high-quality 3D characters from a single image has become a critical need in fields like virtual reality, gaming, and filmmaking. Traditional methods, however, often struggle with limited decomposability, time-consuming optimization, and inconsistent quality. Enter StdGEN, a revolutionary pipeline that generates customizable, semantically decomposed 3D characters in a matter of minutes. By integrating cutting-edge technology, StdGEN addresses these challenges, offering a powerful solution for generating 3D characters that are both detailed and easily modifiable.
The Power of Semantic Decomposition in 3D Character Creation
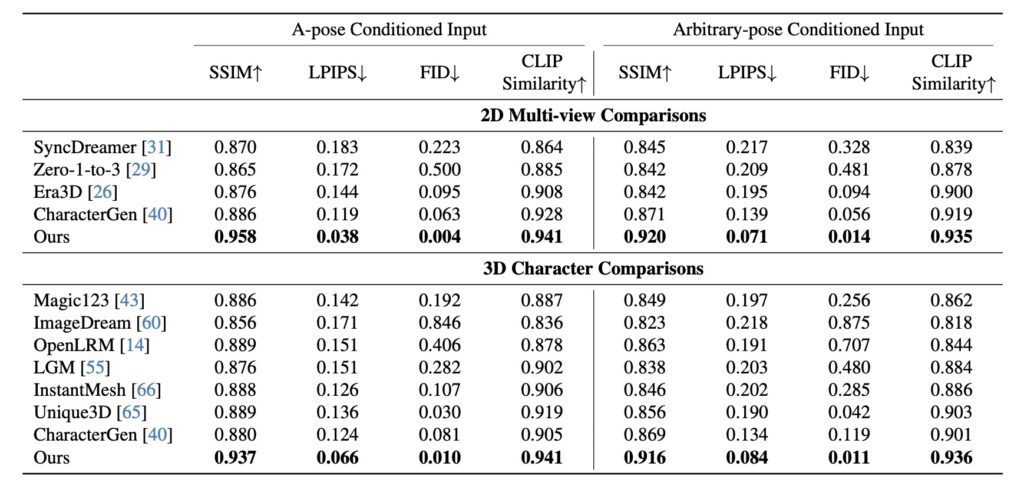
One of StdGEN’s standout features is its ability to decompose 3D characters into distinct semantic components—body, clothes, and hair—providing unprecedented control for designers and developers. This level of semantic separation makes it easier to edit, animate, and integrate 3D characters into various applications. For instance, a game developer can quickly modify a character’s clothing without affecting other elements, while a VR artist can adjust hair or body features independently, making StdGEN ideal for creating dynamic, interactive characters.

Core Technology: Semantic-aware Large Reconstruction Model (S-LRM)
At the heart of StdGEN is the Semantic-aware Large Reconstruction Model (S-LRM), a transformer-based model that generalizes across multiple views to reconstruct geometry, color, and semantics. This model operates in a feed-forward manner, producing high-quality 3D representations with remarkable speed. To extract these semantic layers, StdGEN employs a differentiable multi-layer semantic surface extraction scheme, which captures detailed meshes from the hybrid implicit fields generated by S-LRM. The result is a clean and efficient extraction process, yielding 3D characters with high fidelity and accurate texture.


Superior Performance and Efficiency
Compared to existing models, StdGEN delivers significantly improved geometry, texture, and decomposability. By incorporating an efficient multi-view diffusion model and a multi-layer surface refinement module, StdGEN ensures that characters are generated with the highest quality possible, even from arbitrary-posed single images. In testing, StdGEN consistently outperformed traditional methods in generating complex 3D characters, particularly in the realm of 3D anime character creation, where fine details and precise geometry are essential.


Applications and Customization Potential
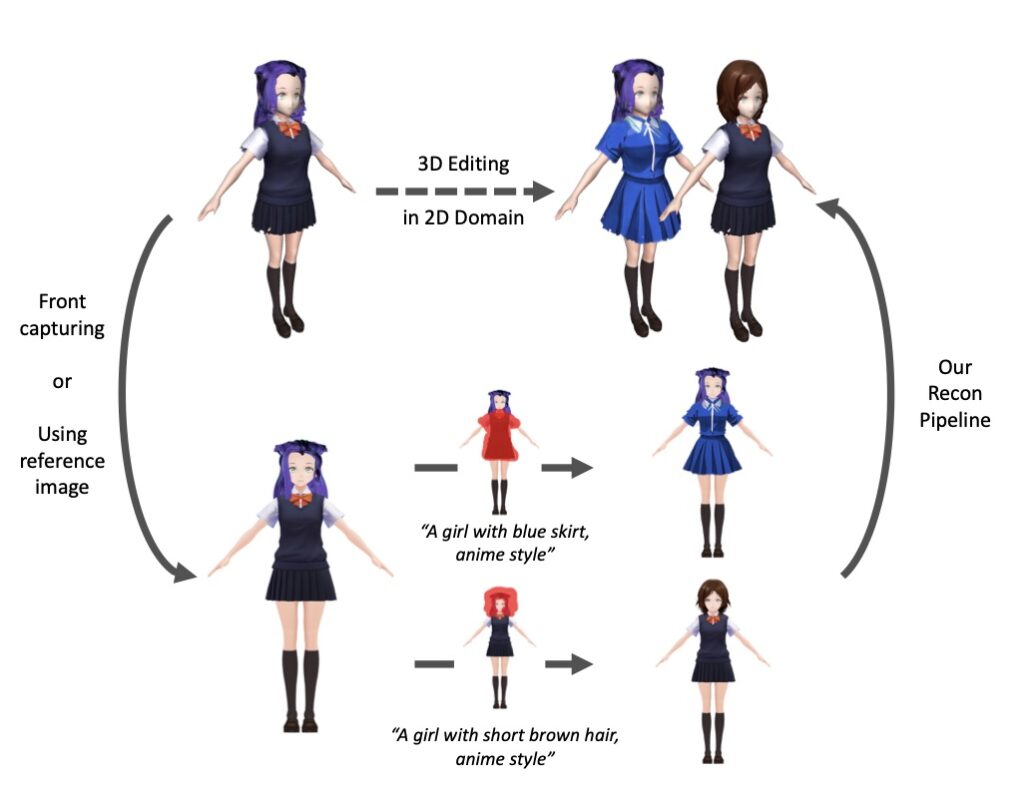
With its ready-to-use 3D characters and flexible customization options, StdGEN offers broad applications across multiple industries. Artists and developers in gaming, film, and VR can leverage StdGEN to create dynamic characters that can be easily edited and animated. The semantic decomposition also enables advanced use cases like swapping outfits or hairstyles, adjusting textures, or reposing characters—tasks that are particularly valuable in content-driven environments.
StdGEN represents a significant breakthrough in 3D character generation, delivering a fast, high-quality solution that combines advanced semantic decomposition with powerful reconstruction models. By offering customizable, semantically decomposed 3D characters, StdGEN is set to transform workflows in VR, gaming, and beyond, enabling a new level of creative control and efficiency for digital artists and developers alike.