Leveraging Multifaceted Rationales for Superior Performance
- Unified Transformer Model: Meteor leverages the Mamba architecture to efficiently embed multifaceted rationales.
- Enhanced Performance: Significant improvements in vision-language tasks without increasing model size or using additional encoders.
- Future Directions: Addressing limitations in model size for users without high-end GPUs and exploring further efficiency techniques.
The field of large language and vision models (LLVMs) has seen rapid advancements driven by the need for realistic generation results and personalized applications. However, progress in audio-to-visual and visual-to-audio generation has been relatively slow. Enter Meteor, a new LLVM leveraging the Mamba architecture for efficient rationale embedding, promising significant improvements in vision-language performance without the need for scaling up model size or incorporating additional vision encoders.

Unified Transformer Model
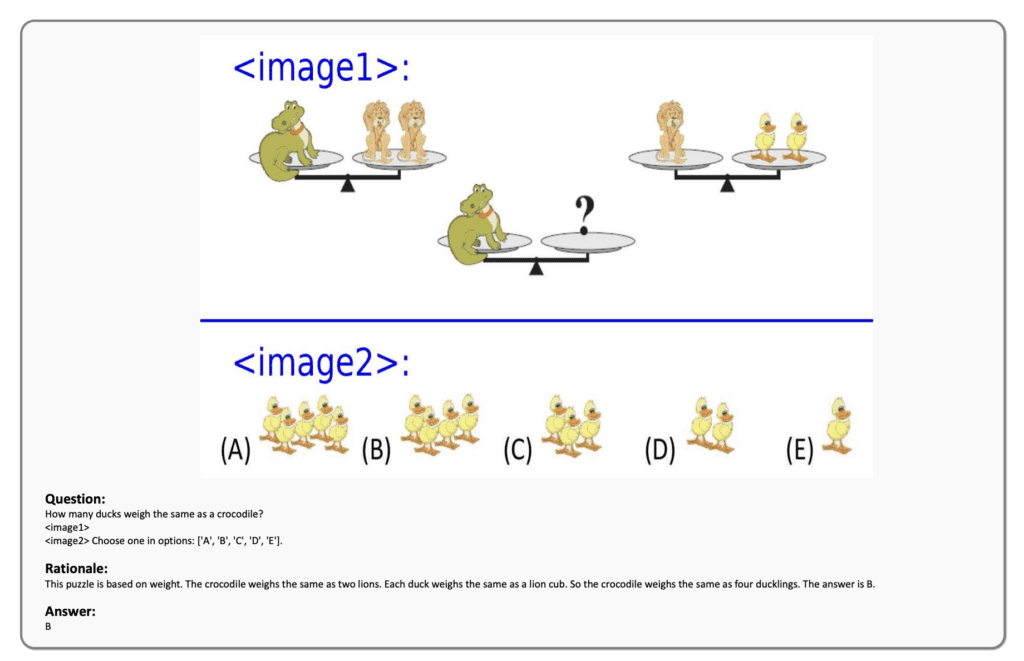
Meteor’s key innovation lies in its use of the Mamba architecture, which processes sequential data with linear time complexity, making it highly efficient. The model employs a novel concept known as the “traversal of rationale,” enabling it to embed lengthy and multifaceted rationales. This approach helps the model understand and respond to complex queries by integrating diverse information such as fundamental image understanding, real-world knowledge, and step-by-step procedures for solving intricate problems.
This multifaceted rationale is embedded within the model, enhancing its ability to generate accurate and contextually relevant answers. The traversal of rationale mechanism facilitates the efficient embedding of rationales, ensuring that the model maintains high performance without the need for additional computational resources.
Enhanced Performance
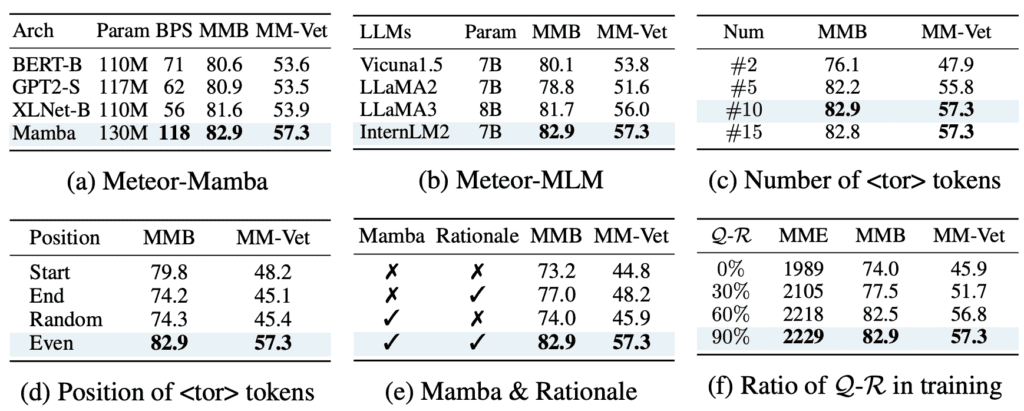
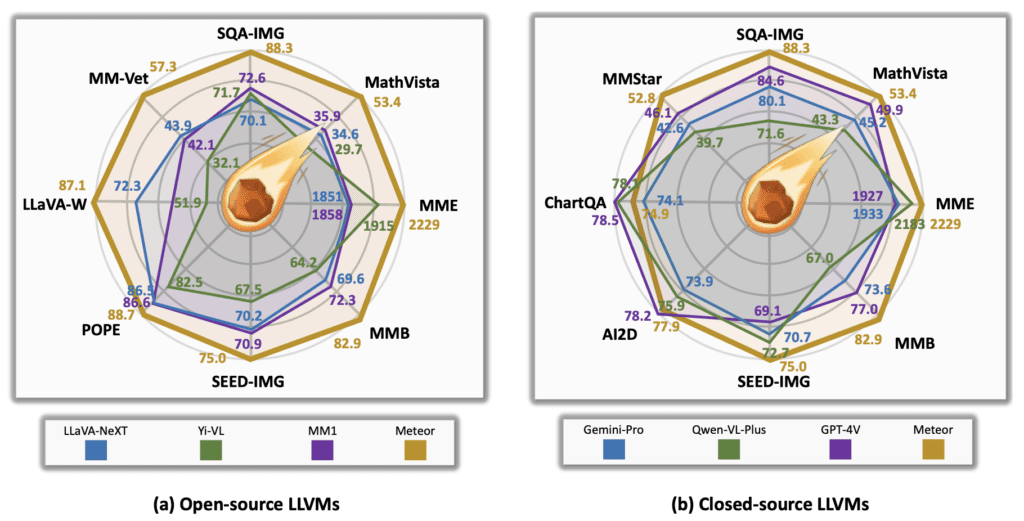
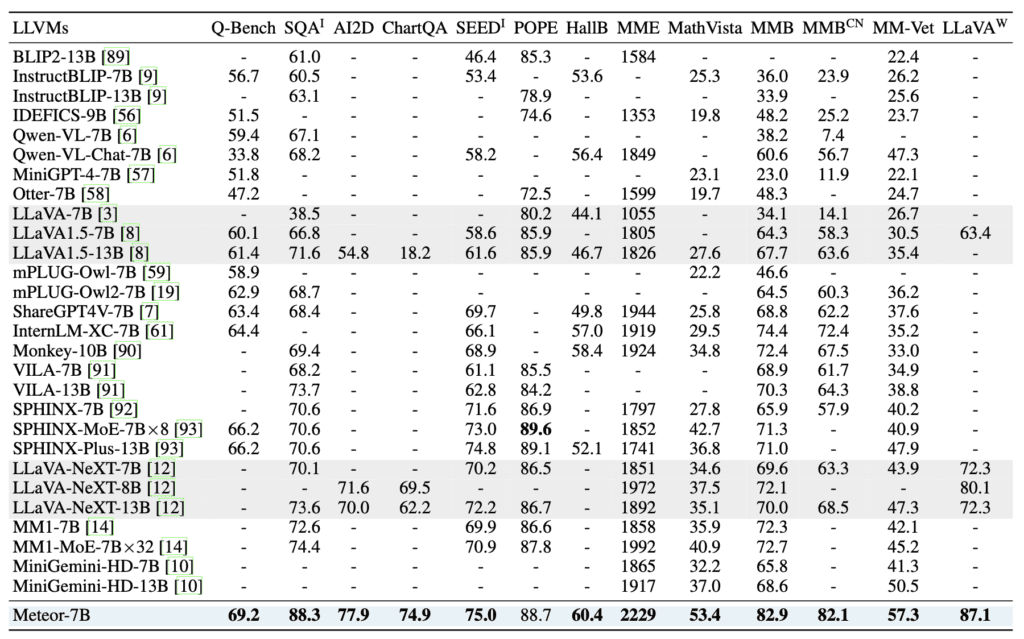
Meteor’s performance across various benchmarks is noteworthy. The model has shown significant improvements in vision-language tasks, outperforming recent methods without the need to scale up the model size or employ additional vision encoders and computer vision models. The use of classifier-free guidance further enhances Meteor’s capabilities, enabling it to generate accurate answers with the aid of embedded rationales.
To validate the effectiveness of the rationale embedding, a thorough analysis was conducted. The results demonstrated that Meteor-Mamba effectively embeds rationales, with the output features containing multifaceted information even without explicit rationales in natural language. This capability allows Meteor to operate efficiently during inference, maintaining high performance across multiple evaluation benchmarks.
Future Directions
Despite its impressive performance, Meteor has some limitations. The model requires multiple GPUs with high VRAM for training and inference, which may be a constraint for users without access to high-end GPU resources. Addressing this issue involves exploring techniques such as mixture of depths and layer-analyzing approaches to reduce model size while maintaining performance.
Additionally, the current model’s image generation quality is limited by the generalization abilities of the pre-trained VQGAN on specific datasets. Future work should focus on improving dataset quality and exploring fine-grained control mechanisms to enhance the model’s real-world applicability.
Meteor marks a significant step forward in the field of LLVMs by adopting a simple and unified transformer approach. It achieves remarkable performance while maintaining efficiency and adaptability. While there are areas for improvement, particularly in reducing model size and enhancing dataset quality, Meteor provides a strong foundation for future research and development in multi-modal generation. As researchers continue to refine and expand upon this model, it promises to unlock new possibilities for integrating visual and audio data in innovative ways.