Why the industry standard for reinforcement learning fails in multi-reward settings, and how a new decoupled approach restores balance to AI training.
- The Hidden Flaw in Standard RL: The industry-standard optimization method (GRPO) accidentally causes distinct reward signals to “collapse” when multiple objectives are combined, leading to poor training stability and model confusion.
- The Decoupled Solution: A new method called GDPO (Group reward-Decoupled Normalization Policy Optimization) solves this by normalizing rewards individually rather than in aggregate, preserving the distinct “resolution” of different human preferences.
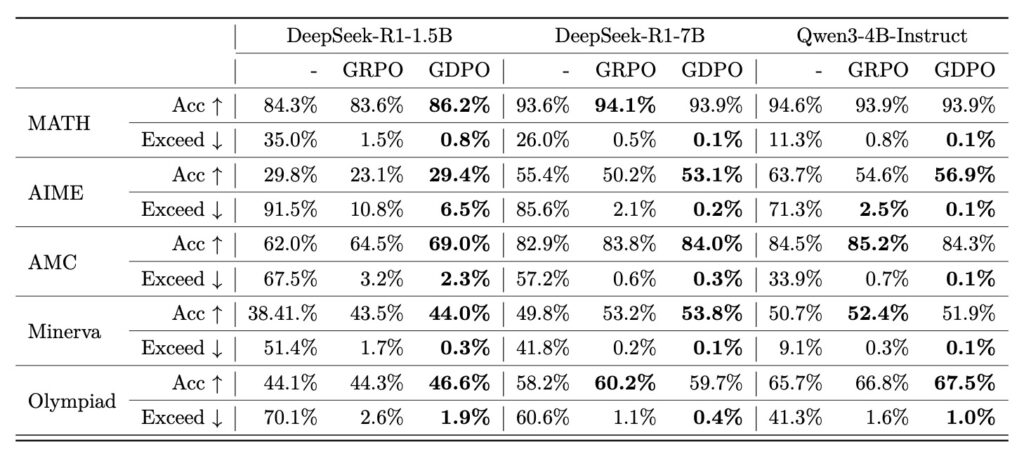
- Superior Performance: Across complex tasks like tool calling, math reasoning, and coding, GDPO consistently outperforms the old standard in both correctness and adherence to strict format constraints.
As Large Language Models (LLMs) evolve from experimental novelties to essential tools, user expectations have shifted dramatically. It is no longer enough for a model to simply be “smart” or factual. Today, users demand models that behave with nuance: they must be accurate, but also concise, safe, coherent, unbiased, and logical.
To achieve this, developers rely on Reinforcement Learning (RL) pipelines. Specifically, they are moving toward multi-reward RL. In this setup, the training process incorporates multiple distinct signals—one reward for safety, another for brevity, a third for code correctness—to guide the model toward a “sweet spot” of behavior that satisfies all diverse human preferences simultaneously.
The Problem with the Status Quo: Why GRPO Fails
Until now, the default engine for this process has been Group Relative Policy Optimization (GRPO). Because of its past successes, researchers have applied GRPO to multi-reward settings without questioning its suitability. A recent study by Nvidia challenges this assumption, revealing a critical mathematical weakness when GRPO is applied to complex, multi-objective problems.
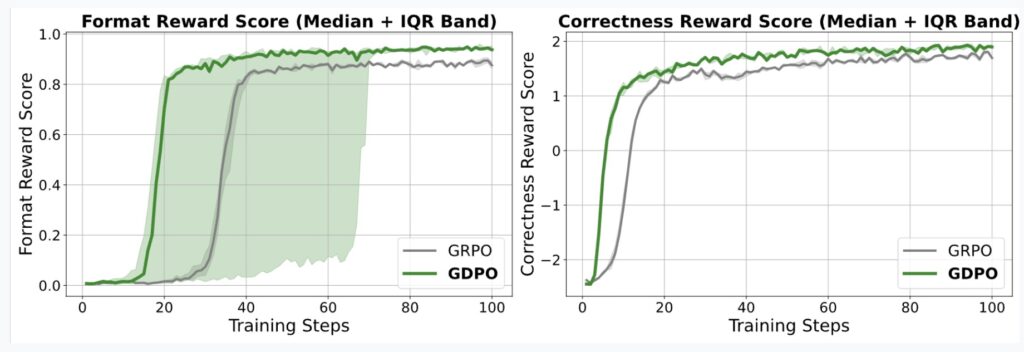
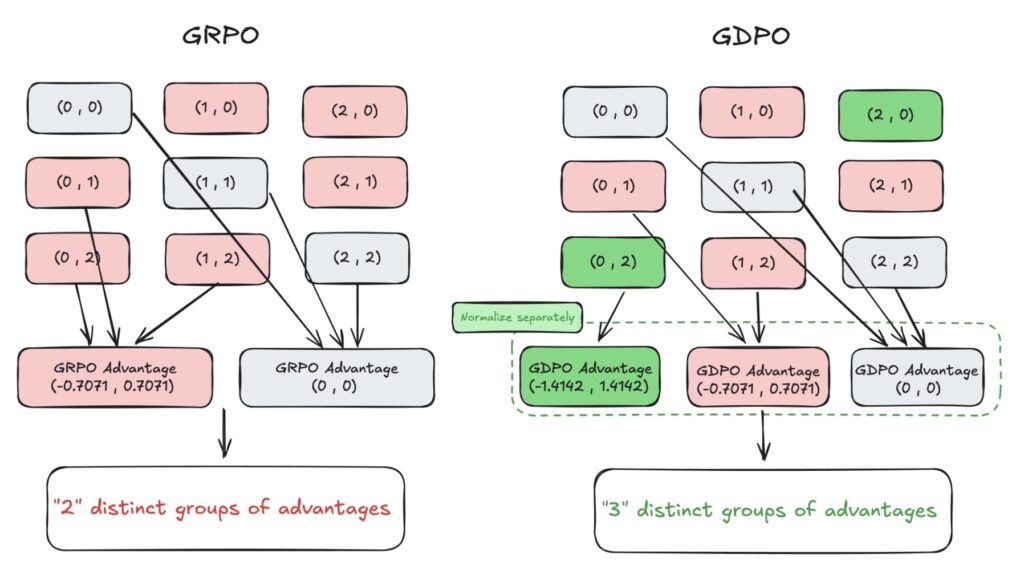
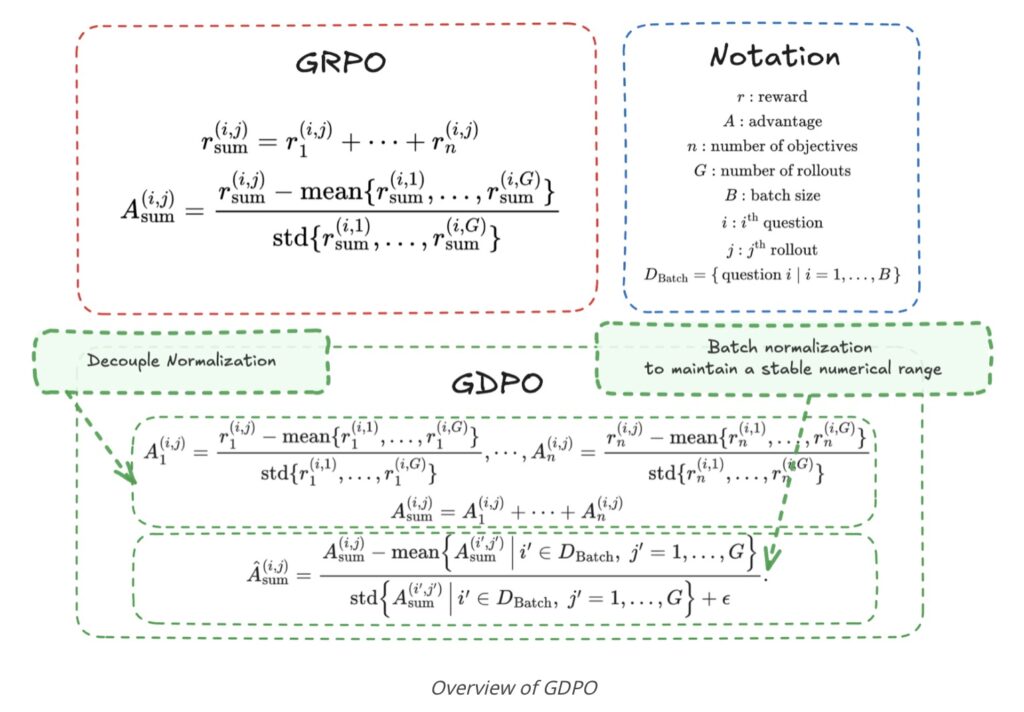
The core issue lies in how GRPO handles normalization. When multiple rewards are summed together before being processed, different combinations of behaviors can accidentally result in identical advantage values. The study describes this as a “collapse,” where the nuances of the training signal are lost.
Imagine trying to teach a student to be both “fast” and “accurate.” If you only give them a single grade based on the average of both, they might not understand that they are failing specifically at accuracy while excelling at speed. The single number obscures the specific feedback. In technical terms, GRPO reduces the resolution of the training signal, leading to suboptimal convergence and, frequently, early training failure.
Enter GDPO: Decoupling for Clarity
To resolve the limitations of the standard approach, the researchers introduced Group reward-Decoupled Normalization Policy Optimization (GDPO).
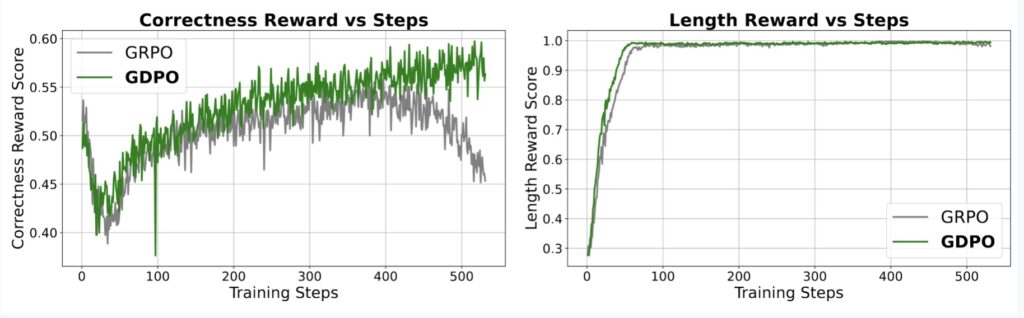
GDPO fundamentally changes how the model processes feedback. Instead of mashing all rewards into a single sum immediately, GDPO performs normalization separately for each individual reward. By decoupling the rewards during this critical phase, the method preserves the relative differences and importance of each objective.
Furthermore, GDPO incorporates batch-wise advantage normalization. This technical addition ensures that as developers add more and more reward types (e.g., adding a “humor” reward on top of “accuracy” and “safety”), the numerical range remains stable. This prevents the model from being overwhelmed by fluctuating values and allows for faithful optimization of the intended preference structure.
Proven Results Across Complex Domains
The effectiveness of GDPO is not just theoretical; it was put to the test in a systematic study comparing it directly against GRPO. The evaluation covered three highly demanding domains:
- Tool Calling: Requiring the model to use external software functions correctly.
- Math Reasoning: Demanding strict logical steps and accurate calculations.
- Coding Reasoning: Evaluating the generation of functional, bug-free code.
The study measured success using two distinct metrics: correctness (accuracy and bug ratios) and constraint adherence(following format rules and length limits).
The results were conclusive: GDPO consistently outperformed GRPO across all settings. Whether the task involved complex logical chains or strict formatting rules, the decoupled approach provided a clearer signal to the model. The study demonstrated that GDPO is not only more accurate but also significantly more stable, avoiding the early training failures that often plague multi-reward GRPO runs.
A New Foundation for Alignment
This research highlights a crucial lesson in AI development: standard tools cannot always be blindly applied to new, more complex problems. As we demand our AI models to juggle an increasing number of human preferences—balancing efficiency with safety, and logic with creativity—the methods we use to train them must evolve.
By recognizing the “collapse” caused by standard optimization and shifting to a decoupled framework, GDPO offers a robust solution for the future of RL. It allows developers to fine-tune reward functions, adjust for difficulty disparities between objectives, and ultimately deliver models that truly align with the complex tapestry of human needs.