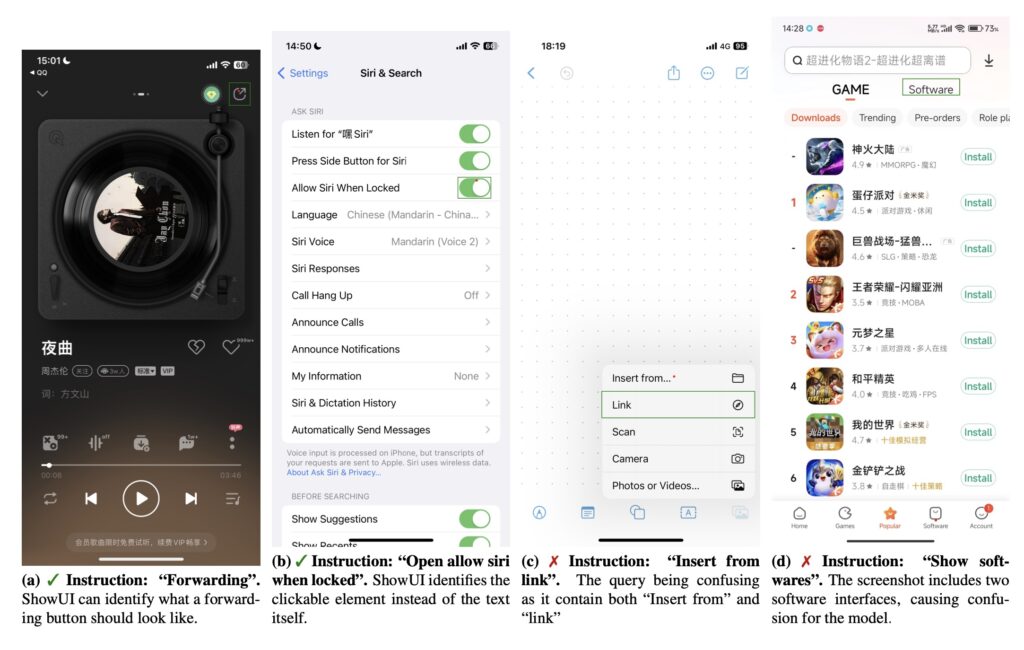
A breakthrough in digital workflow assistants, bridging human-like perception and action for seamless GUI navigation.
- Enhanced Human-Like Interaction: ShowUI introduces a novel vision-language-action model, enabling more intuitive and effective GUI-based assistance.
- Efficient Data and Computational Innovations: The model leverages UI-guided visual token selection, significantly reducing redundant computations and boosting performance speed.
- Performance Across Platforms: Achieving high zero-shot accuracy, ShowUI demonstrates potential in web, mobile, and online navigation tasks.
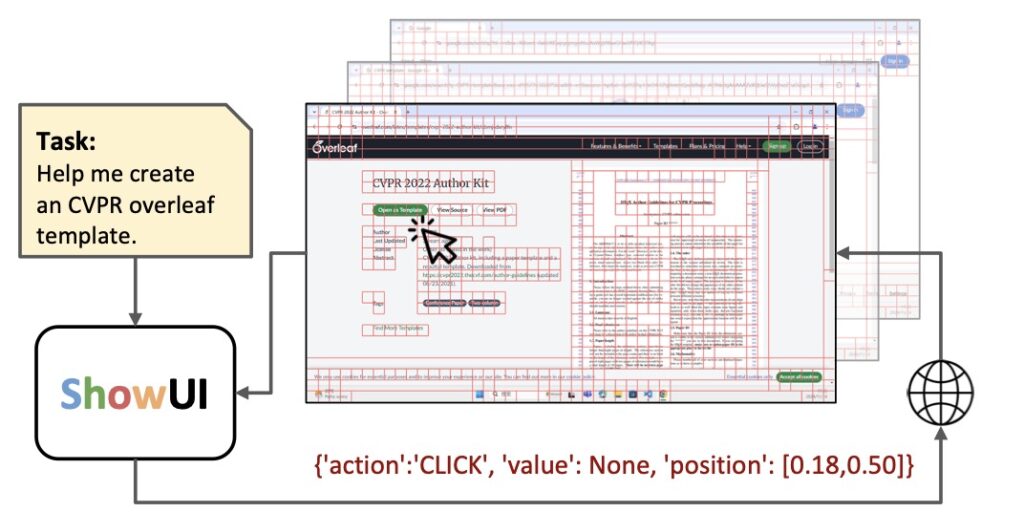
The digital world revolves around graphical user interfaces (GUIs), facilitating countless tasks from browsing to complex application navigation. However, traditional GUI agents, which rely heavily on language-based models and structured APIs, fall short in perceiving and interacting with GUI visuals as humans do. Enter ShowUI, a cutting-edge vision-language-action model designed to bridge this gap.
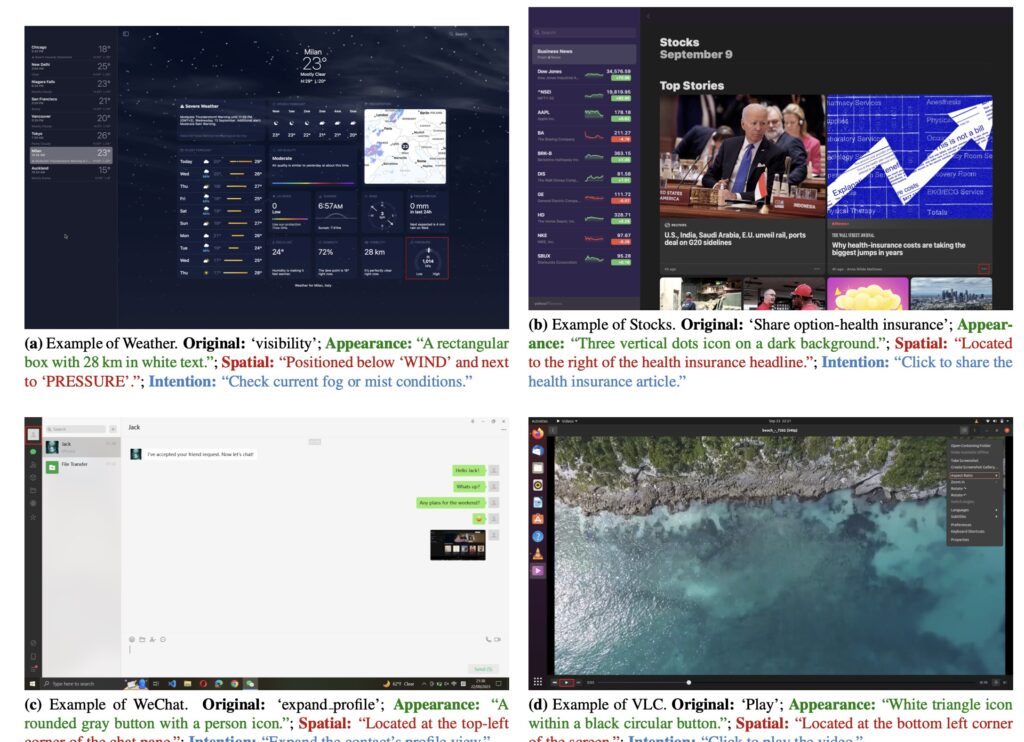
With its revolutionary ability to comprehend visual layouts and take appropriate actions, ShowUI redefines digital workflow assistance. It moves beyond the limitations of traditional agents by integrating innovative components like UI-guided visual token selection and interleaved vision-language-action streaming, making GUI navigation smarter and faster.
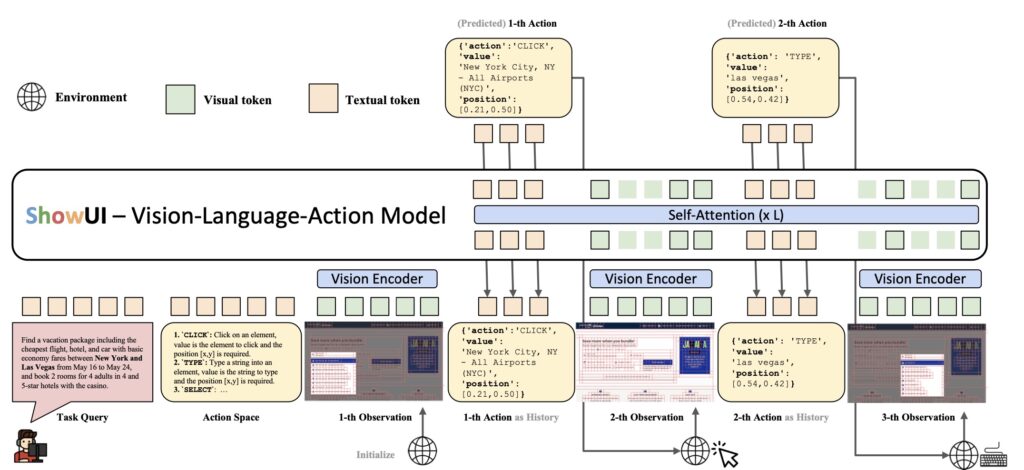
Innovative Features Driving ShowUI
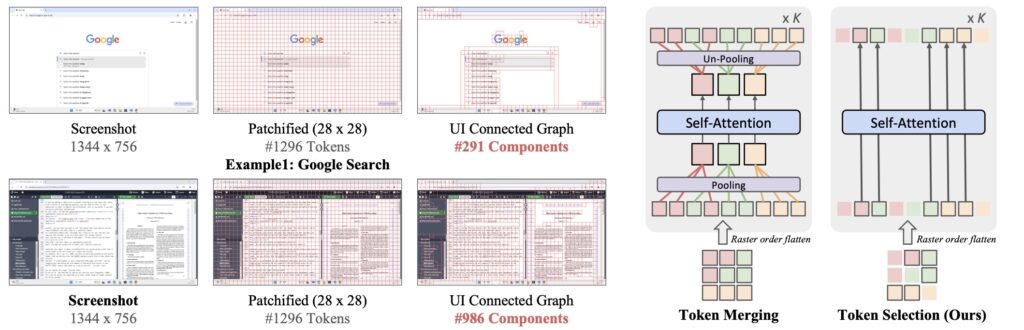
The heart of ShowUI lies in its unique approach to reducing computational overhead without compromising on accuracy. The UI-Guided Visual Token Selection mechanism processes high-resolution UI screenshots by identifying redundant elements, optimizing efficiency, and accelerating training speeds by 1.4×. This feature not only saves computational costs but also ensures the model is lightweight and adaptable.
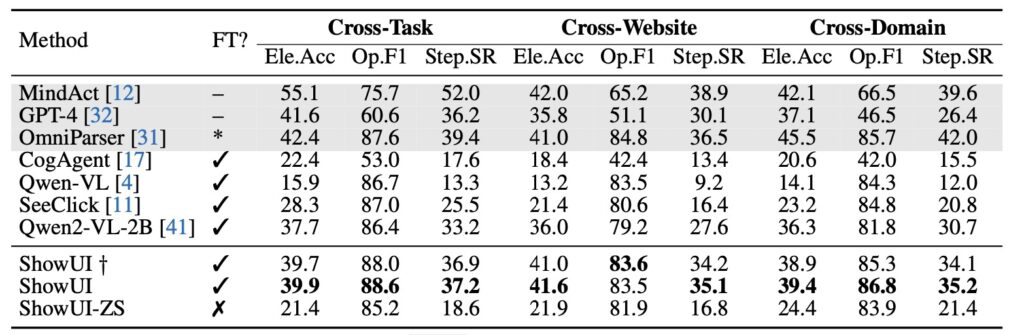
Moreover, the Interleaved Vision-Language-Action Streaming framework enables seamless management of multi-turn interactions and navigation tasks. By pairing visual-action history with queries, the model handles complex GUI workflows with precision. These innovations make ShowUI a versatile tool for tackling diverse GUI environments, whether it’s a web browser, a mobile app, or an online platform.
A Data-Driven Approach for Better Results
ShowUI’s success is also rooted in its carefully curated instruction-following dataset. With a resampling strategy to address data imbalances, the dataset equips the model to perform well across tasks, achieving an impressive 75.1% zero-shot accuracy in screenshot grounding. Despite its lightweight 2B parameter size, ShowUI delivers results on par with larger models, making it a practical solution for real-world applications.

Future Directions: From Offline to Online Mastery
While ShowUI excels in offline environments, its potential extends further. By integrating reinforcement learning in future iterations, the model can adapt to dynamic online environments, refining its capabilities and addressing its current limitations. This evolution could make ShowUI a cornerstone in the development of smarter, more human-like GUI agents.
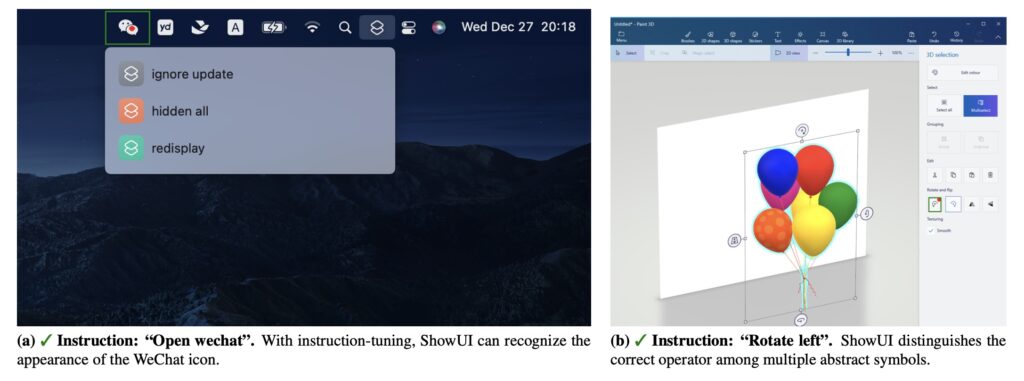
With its innovative architecture, efficient data handling, and versatility across platforms, ShowUI represents a major leap forward in GUI automation. It promises to streamline workflows, enhance productivity, and pave the way for intelligent digital assistants that truly understand and act on user intentions.