By shifting from discrete symbols to continuous vectors, the Continuous Autoregressive Language Model (CALM) promises massive compute savings and a fundamental leap in generative efficiency.
- The Death of the Next-Token Paradigm: CALM bypasses the traditional vocabulary softmax bottleneck, using a high-fidelity autoencoder to compress chunks of text into a single continuous vector with over 99.9% reconstruction accuracy.
- Massive Efficiency Gains: By predicting the “next vector” instead of the next word, each generative step carries 4× the semantic bandwidth, successfully reducing training compute by 44%.
- A New Frontier for AI Development: Moving away from discrete tokens requires an entirely new likelihood-free toolkit, opening massive new research opportunities in scaling laws, sampling methods, and model training.
For years, the artificial intelligence industry has been locked into a single, foundational paradigm: next-token prediction. From the earliest breakthroughs to today’s state-of-the-art Large Language Models (LLMs), the core mechanism has remained an autoregressive generation process that types out responses one discrete symbol at a time. While this approach has yielded unprecedented reasoning and linguistic capabilities, it comes with a massive, prohibitive cost. Predicting single tokens through a massive vocabulary softmax layer is incredibly slow, computationally expensive, and scales poorly as context windows grow.
Now, researchers from Tencent and Tsinghua University have introduced a solution that completely disrupts this status quo. They have released CALM—Continuous Autoregressive Language Models—and we are quite literally watching language models evolve from typing discrete symbols to streaming continuous thoughts.
The Shift to Semantic Bandwidth
To understand why CALM is so revolutionary, it helps to look at the history of language modeling. Early models operated at the character level, struggling under the immense computational weight of extremely long sequences. The industry then shifted to subword tokenization, driven by a simple realization: increasing the information density—or “semantic bandwidth”—of each text unit dramatically reduces sequence length and boosts efficiency.
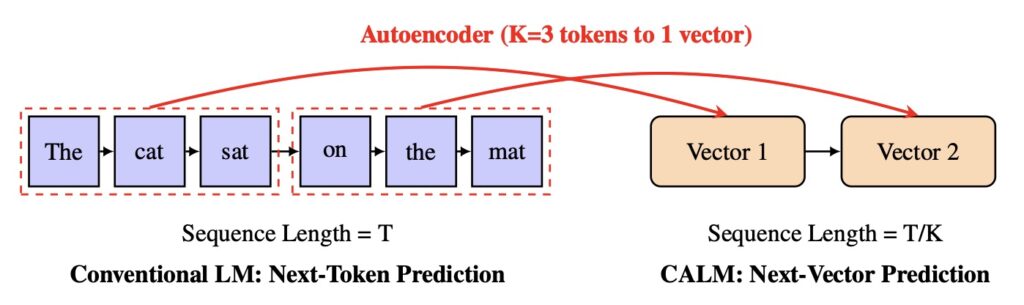
CALM takes this historical evolution to its ultimate logical conclusion. It challenges the inefficient token-by-token bottleneck by bypassing the vocabulary entirely. Instead of predicting a discrete token, CALM utilizes a high-fidelity autoencoder to compress a chunk of text into a single continuous vector. From this vector, the original tokens can be reconstructed with over 99.9% accuracy.
The model is then trained to predict the “next vector” in a continuous space. The numbers backing this up are staggering. By packaging multiple tokens into one continuous step, each generative action carries four times the semantic bandwidth. The dreaded softmax bottleneck is completely removed, resulting in a 44% reduction in training compute while maintaining the performance of strong discrete baselines.
Building a New Algorithmic Toolkit
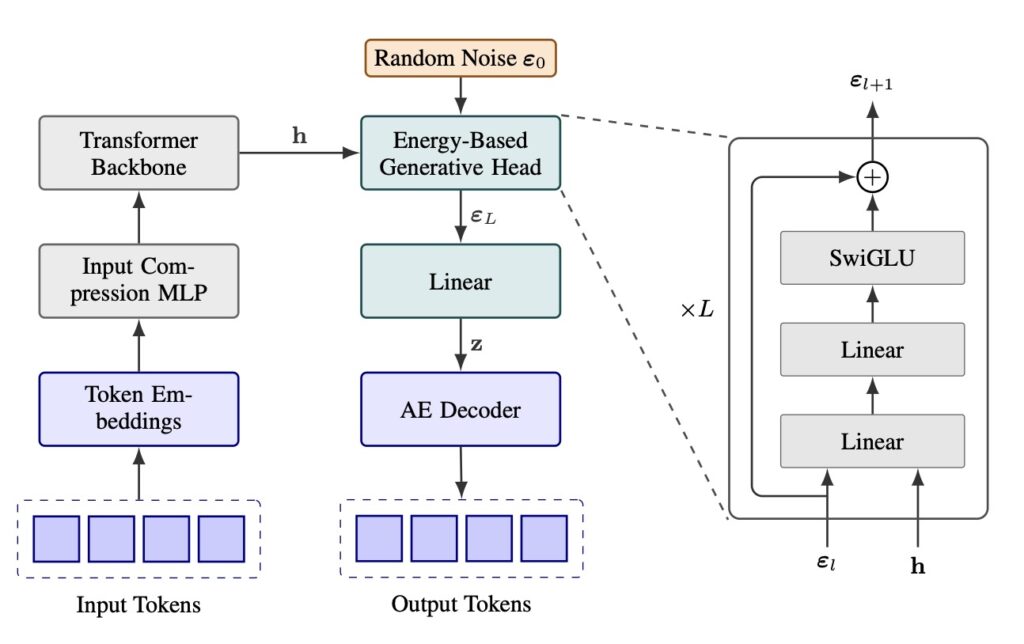
When you fundamentally change how an AI model generates language, you also break all the tools built for the old system. Because CALM operates in a continuous domain rather than calculating the probability of discrete words, the standard LLM algorithmic toolkit had to be entirely rebuilt.
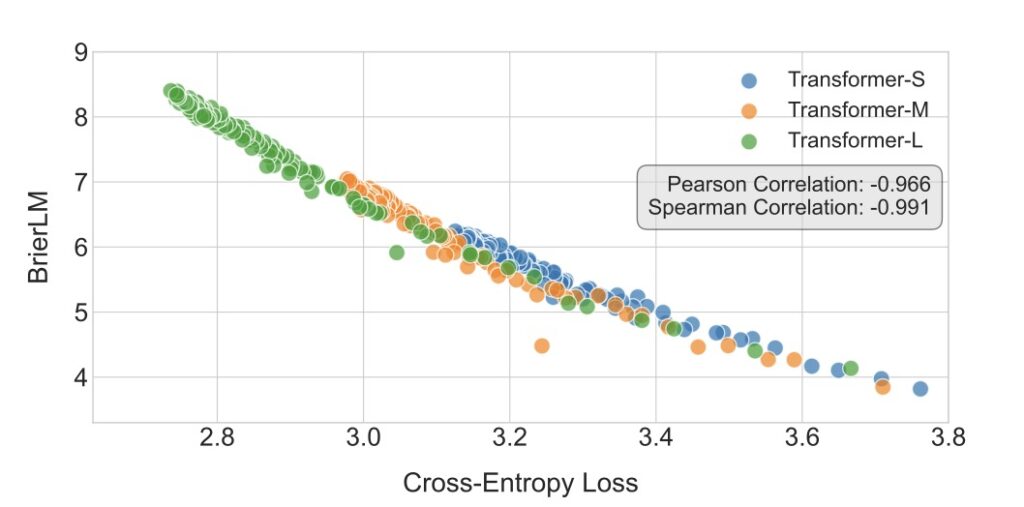
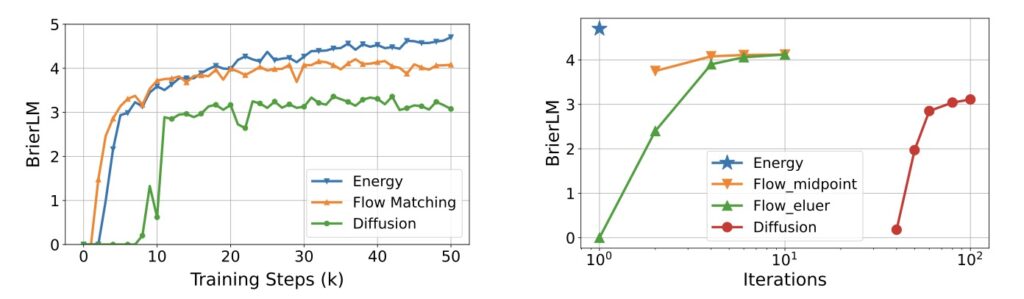
The researchers developed a comprehensive likelihood-free framework to make this work. This includes a robust energy loss function for generative modeling, a new metric called BrierLM for evaluation, and a novel suite of algorithms for temperature sampling. This establishes next-vector prediction not just as an interesting experiment, but as a fully operational and scalable pathway toward ultra-efficient language models.
Optimization and Scaling
While CALM represents a massive leap forward, it is still in its infancy, with immense room for architectural and algorithmic optimization. The research team has already identified several key frontiers that will define the next wave of AI development:
- Smarter Autoencoders: The current autoencoder focuses heavily on perfect reconstruction. Future iterations aim to build a semantically grounded latent space, much like recent trends in computer vision, where proximity in the vector space corresponds directly to semantic similarity. Context-aware or autoregressive designs could make this even more robust.
- Architectural Evolution: Currently, CALM uses a Transformer backbone paired with a lightweight generative head. The next step is exploring fully integrated, end-to-end generative Transformers that might yield even stronger modeling capabilities.
- Lightweight Inference: CALM’s current likelihood-free temperature sampling relies on rejection sampling, which introduces some inference overhead. Developing lightweight heuristic methods to navigate the trade-off between diversity and fidelity during inference will be crucial for real-world deployment.
- New Scaling Laws: Traditional AI scaling laws evaluate performance based on model and data size. CALM introduces a third variable: the semantic bandwidth of the chunked tokens. Formulating unified scaling laws will allow developers to pinpoint the exact optimal configuration for any given compute budget.
- Reinventing RLHF and Distillation: Popular techniques like Reinforcement Learning from Human Feedback (RLHF) and knowledge distillation rely on increasing log-probabilities or minimizing divergences between probability distributions—things CALM cannot directly compute. Reformulating these critical alignment techniques to work in a continuous, sample-based regime is one of the most exciting challenges ahead.
The transition from discrete tokens to continuous vectors isn’t just a clever optimization trick; it is a fundamental shift in the trajectory of artificial intelligence. By allowing models to process and generate language in broader semantic strokes, CALM is tearing down the primary barrier to faster, cheaper, and vastly more capable AI.