How Distilling Transformers into Linear RNNs Enhances Performance and Speeds Up Inference.
- Distilling Transformers into Linear RNNs: The research demonstrates that it is possible to convert large Transformer models into more compact linear RNNs without significant loss in performance. This conversion leverages the weights from Transformer attention layers and showcases that these distilled models can achieve comparable results to their larger counterparts.
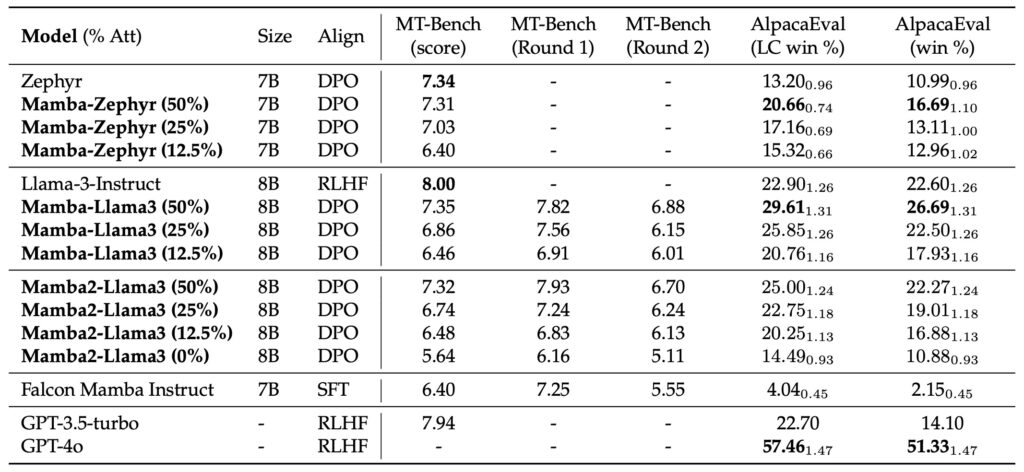
- Hybrid Models Outperforming Originals: The newly developed hybrid model, which retains only a fraction of the original attention layers, not only matches the performance of the full Transformer models in chat benchmarks but also surpasses existing open-source hybrid models in both chat and general benchmarks.
- Enhanced Inference Speed with Speculative Decoding: The introduction of a hardware-aware speculative decoding algorithm significantly accelerates the inference speed of the distilled models. This advancement allows the hybrid models to deliver high performance while being more resource-efficient.
In the quest for more efficient AI systems, researchers have unveiled a transformative approach that combines the best of both worlds: the robustness of Transformers and the speed of linear RNNs. This innovative method, dubbed “The Mamba in the Llama,” reveals how distilling large Transformer models into linear RNNs can achieve superior performance and faster inference.
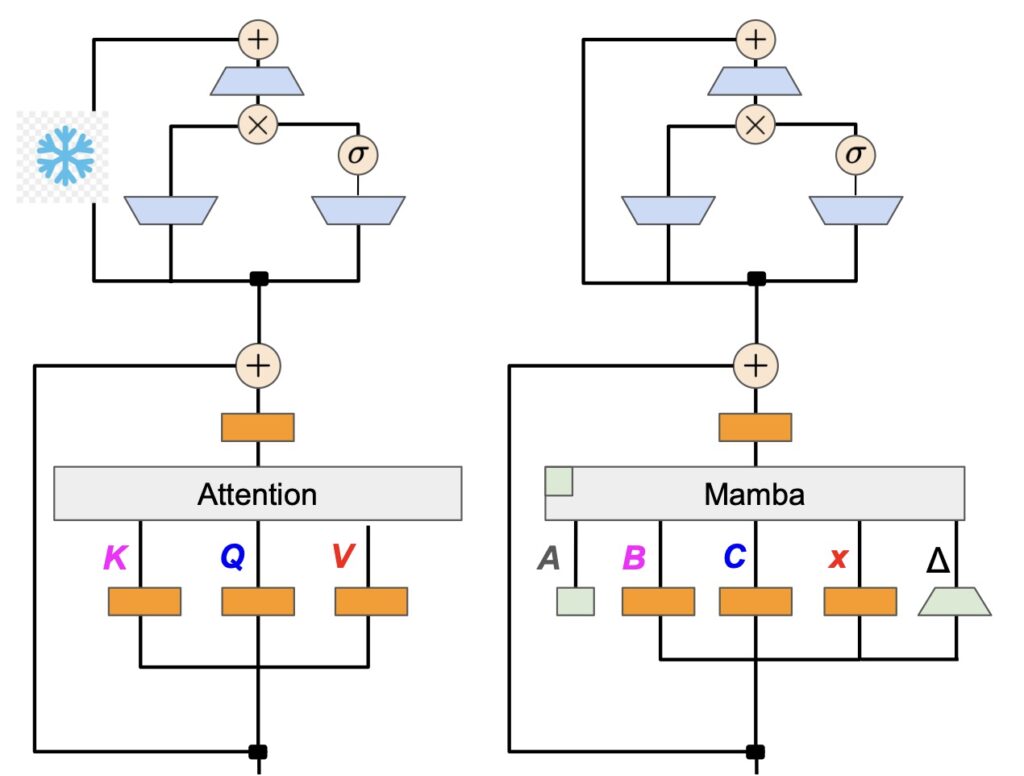
From Transformers to Linear RNNs: A Strategic Conversion
The traditional Transformer models, known for their state-of-the-art language capabilities, require immense computational resources for training and deployment. The breakthrough research demonstrates that these large-scale models can be distilled into linear RNNs, known as Mamba models, while preserving their core functionalities. By reusing linear projection weights from the attention layers, researchers have successfully converted Transformers into a more streamlined form that retains competitive performance.
Hybrid Models: More Efficient, Yet Highly Effective
The hybrid model, resulting from this distillation process, significantly reduces the number of attention layers compared to the original Transformer. Remarkably, this reduced model still performs on par with full Transformer models in chat-based evaluations. In fact, it outperforms several open-source hybrid Mamba models trained from scratch, highlighting its efficiency and effectiveness. This advancement not only challenges the conventional reliance on expansive Transformer models but also demonstrates the potential for achieving high performance with fewer resources.
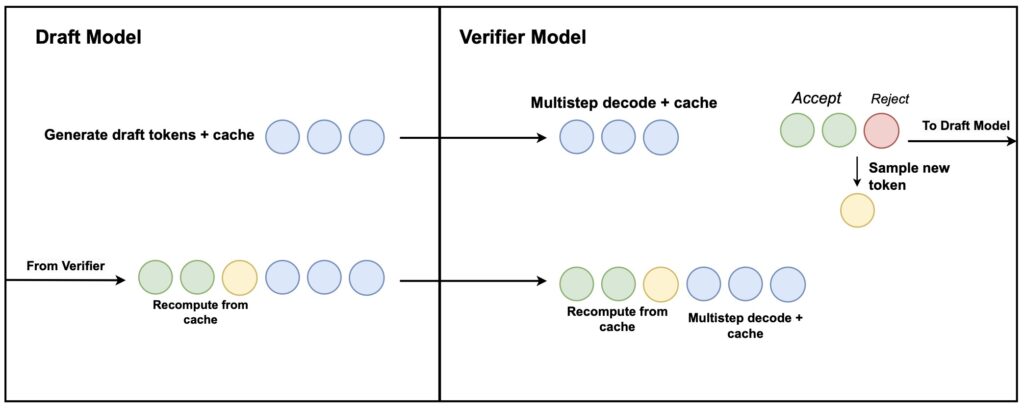
Speculative Decoding: Turbocharging Inference
A key innovation in this research is the introduction of a hardware-aware speculative decoding algorithm. This method accelerates the inference process for the hybrid models, making them faster and more resource-efficient. The speculative decoding technique optimizes the model’s performance during deployment, reducing latency and computational load while maintaining the accuracy of language generation.

The research reveals a promising direction for future AI model deployment. By combining distillation techniques with advanced decoding strategies, the study paves the way for more adaptable and efficient language models. The top-performing distilled model, based on Llama3-8B-Instruct, not only competes with leading models like GPT-4 but also demonstrates the potential for optimizing LLMs beyond traditional attention mechanisms. This innovative approach opens new avenues for developing customized AI solutions that balance performance and computational efficiency.