A revolutionary hybrid architecture finally bridges the gap between fast diffusion and smart autoregression.
- The Best of Both Worlds: TiDAR combines the parallel processing speed of diffusion models with the high-quality output of autoregressive models (like GPT) in a single forward pass.
- Massive Speed Gains: The architecture delivers nearly 6x faster performance at 8B parameters without sacrificing quality, outperforming current speculative decoding methods.
- Smart Resource Usage: By exploiting “free slots” in modern GPUs, TiDAR drafts multiple tokens simultaneously while verifying them instantly, making it ideal for real-time AI agents.
For years, the development of Large Language Models (LLMs) has been stuck in a frustrating tug-of-war between speed and intelligence. On one side, you have Autoregressive (AR) models—the technology behind heavy hitters like GPT-4. They are incredibly smart and coherent because they generate text sequentially, one word at a time. However, this method is inherently slow and inefficient, often leaving vast amounts of GPU power sitting idle as the hardware waits for the next token to be calculated.
On the other side are Diffusion models. These are the speed demons of the AI world, capable of generating data in parallel. While they excel at speed, they have historically struggled with language, often producing output that lacks the coherence and logical flow of their AR counterparts.
NVIDIA has just dropped a paper that might finally solve this “Speed vs. Quality” trade-off. They call it TiDAR, and it represents a fundamental shift in how AI thinks and talks.
The Architecture of Efficiency: Thinking and Talking Simultaneously
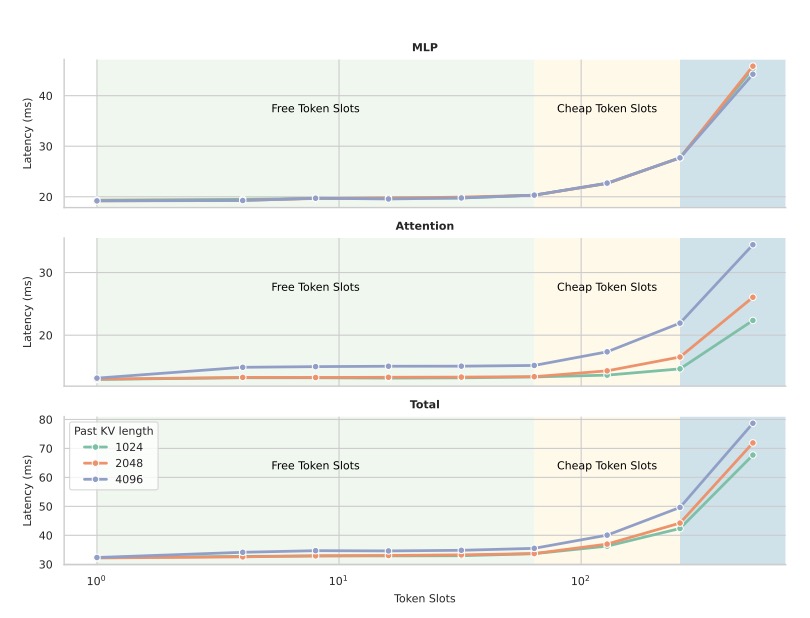
TiDAR stands for “Thinking in Diffusion, Talking AutoRegressively.” The genius of this architecture lies in its ability to do two things at once, effectively utilizing the “free slots” of computational power that modern GPUs usually waste during standard processing.
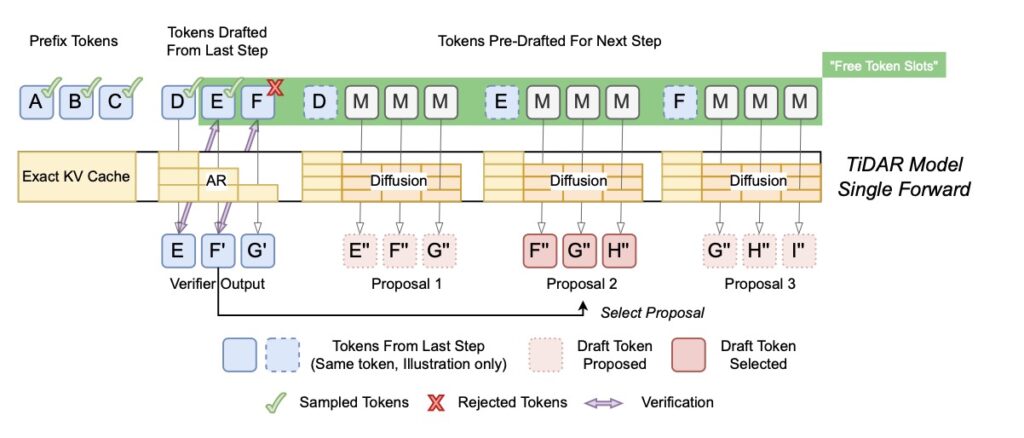
In a traditional setup, an AI model works linearly. TiDAR, however, employs a sequence-level hybrid architecture that executes a “Thinking” phase and a “Talking” phase within a single forward pass.
- The “Thinking” Phase (Diffusion): TiDAR uses diffusion to draft multiple tokens at once. Instead of guessing the next word, it drafts a whole sequence in parallel. This is the “thinking” part, where the model sketches out the potential future of the sentence.
- The “Talking” Phase (Autoregression): Simultaneously, the model uses autoregression to verify these drafted tokens. This ensures the output maintains the high quality and causal logic we expect from top-tier LLMs.
This simultaneous processing is made possible by smart attention masks—using bidirectional attention for the drafting phase and causal attention for the verification phase.
Breaking the Speed Limit
The results of this hybrid approach are nothing short of staggering. In the quest for Artificial General Intelligence (AGI), the ability to scale computation efficiently is paramount. TiDAR proves that we don’t need to sacrifice quality to get there.
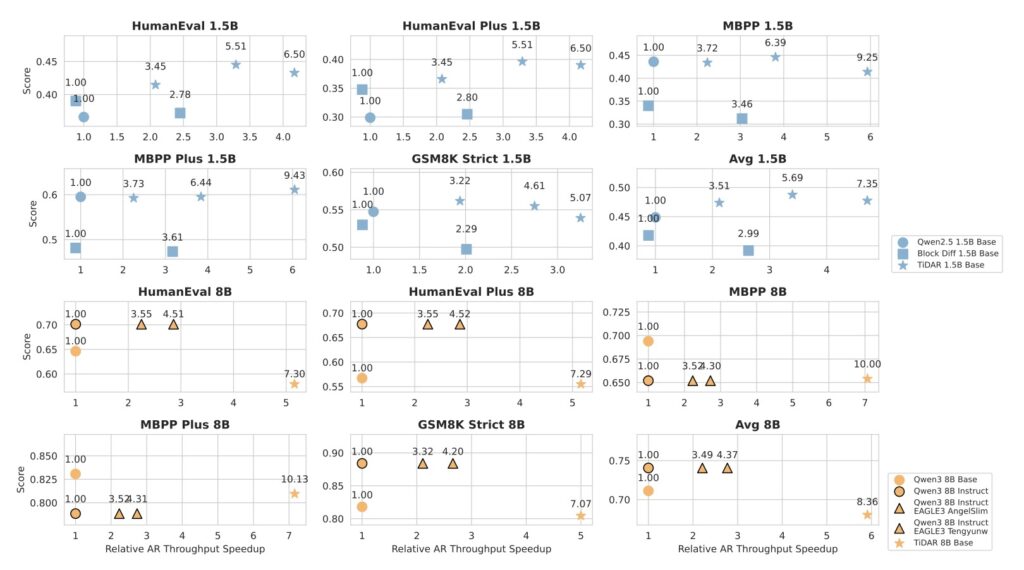
At the 1.5 billion parameter scale, TiDAR runs 4.71x faster than standard autoregressive models with zero loss in quality. When scaled up to 8 billion parameters, the speed advantage jumps to nearly 6x (5.91x).
Perhaps most impressively, TiDAR is the first architecture to outperform speculative decoding (specifically EAGLE-3), which was previously the gold standard for speeding up LLMs. Unlike speculative decoding, which relies on a weaker, separate model to draft text, TiDAR handles everything internally with greater efficiency.
A New Standard for Real-Time AI
The implications for developers and the broader AI industry are significant. Current methods often fail to balance the equation; they either prioritize AR and suffer from memory bottlenecks, or they lean into diffusion and lose coherence. TiDAR closes this quality gap.
Furthermore, the training method is remarkably clever. Instead of randomly masking tokens—a common technique in training—TiDAR masks everything. This provides stronger learning signals and enables efficient single-step drafting. It also works seamlessly with standard KV caching, a feature that pure diffusion models typically lack, making it highly “serving-friendly” for engineers deploying these models in the real world.
For anyone building real-time AI agents where latency kills the user experience, TiDAR is a game-changer. By pushing the limits of GPU compute density, NVIDIA has shown that we can finally have an AI that thinks as fast as it talks.
