Large Language Models Are Vulnerable to Stealthy Attacks That Undermine Safety Alignment
- Guardrails Aren’t Enough: Despite guardrail moderation systems designed to filter harmful data, a new attack method called Virus can bypass these defenses with up to 100% success, exposing critical vulnerabilities in Large Language Models (LLMs).
- Dual-Objective Optimization: Virus uses a sophisticated dual-goal optimization technique to both evade detection by guardrails and maintain the harmful impact on the model, effectively breaking its safety alignment.
- A Wake-Up Call for AI Safety: The research highlights the urgent need for more robust safety mechanisms, as current guardrail systems are insufficient to protect LLMs from harmful fine-tuning attacks.
Large Language Models (LLMs) like OpenAI’s GPT and Meta’s LLaMA have revolutionized the way we interact with AI. These models are fine-tuned to align with human values, ensuring they provide helpful, safe, and ethical responses. However, recent research has uncovered a disturbing vulnerability: harmful fine-tuning attacks. These attacks involve injecting malicious data into the fine-tuning process, causing the model to lose its safety alignment and potentially generate harmful or dangerous outputs.
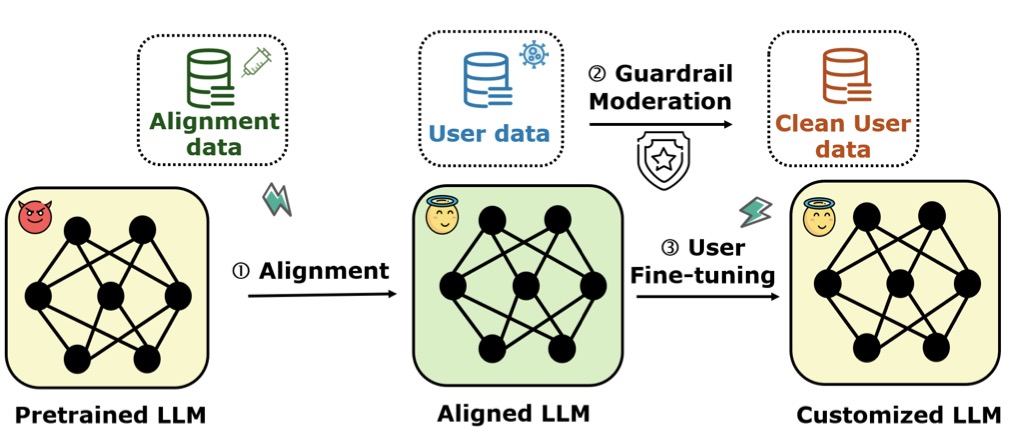
To mitigate this risk, AI developers have introduced guardrail moderation systems. These systems act as filters, scanning fine-tuning data for harmful content before it is used to update the model. While guardrails have been effective in blocking obvious threats, a new study reveals that they are far from foolproof. Enter Virus, a novel attack method that can bypass these guardrails with alarming ease.
A Stealthy Bypass
The Virus attack method is a sophisticated red-teaming technique designed to exploit the weaknesses of guardrail moderation. The researchers behind Virus discovered that by slightly modifying harmful data, they could trick the guardrail into classifying it as benign. This allows the harmful data to slip through undetected, effectively poisoning the fine-tuning process.
The key innovation of Virus lies in its dual-objective optimization approach. The attack optimizes harmful data to achieve two goals simultaneously:
- Evading Detection: The modified data is designed to minimize the guardrail’s ability to detect it as harmful, achieving a 100% leakage ratio in some cases.
- Maintaining Harmful Impact: The attack ensures that the modified data still retains its harmful properties, allowing it to degrade the model’s safety alignment effectively.

This dual-objective approach is what sets Virus apart from previous attack methods. While earlier attempts to bypass guardrails either failed to evade detection or lost their harmful impact, Virus strikes a delicate balance, making it a potent threat to LLM safety.
The Failure of Guardrails: A False Sense of Security
The study begins by validating the effectiveness of guardrail moderation. In controlled experiments, the researchers found that guardrails could filter out 62% of harmful data, significantly reducing the risk of harmful fine-tuning attacks. However, this success is short-lived. When the researchers introduced Virus, they observed that 100% of the modified harmful data could bypass the guardrail, rendering the moderation system ineffective.
This finding is particularly alarming because it challenges the assumption that guardrails are a reliable defense against harmful fine-tuning. The researchers emphasize that relying solely on guardrail moderation is reckless, as it fails to address the inherent vulnerabilities of pre-trained LLMs.
The Broader Implications for AI Safety
The implications of this research extend far beyond the technical realm. As LLMs become increasingly integrated into our daily lives—powering everything from customer service chatbots to medical diagnosis tools—the risks posed by harmful fine-tuning attacks grow exponentially. A compromised model could generate harmful content, spread misinformation, or even provide dangerous instructions, all while appearing to function normally.
The study serves as a wake-up call for the AI community. While guardrails are an important first line of defense, they are not sufficient on their own. The researchers call for a multi-layered approach to AI safety, combining improved guardrail systems with more robust alignment techniques and continuous monitoring of fine-tuning processes.

Strengthening AI Defenses
The discovery of the Virus attack method underscores the need for ongoing research into AI safety. The researchers propose several potential solutions to mitigate the risks posed by harmful fine-tuning attacks:
- Enhanced Guardrail Systems: Developing more advanced moderation models that can detect subtle modifications in harmful data.
- Gradient-Based Defenses: Implementing mechanisms to monitor and control the gradients used during fine-tuning, ensuring that harmful data cannot alter the model’s behavior.
- Post-Fine-Tuning Audits: Regularly testing fine-tuned models for signs of compromised safety alignment, even after the fine-tuning process is complete.
A Call to Action
The Virus attack method is a stark reminder that AI safety is an ongoing challenge. As LLMs continue to evolve, so too must the defenses that protect them. The researchers behind Virus have made their code and datasets publicly available, encouraging the AI community to scrutinize their findings and develop more robust solutions.
In the race to build smarter and more capable AI systems, we must not lose sight of the importance of safety. The stakes are too high to rely on half-measures. As the study concludes, guardrail moderation is not a silver bullet—it is merely one piece of a much larger puzzle. The time to act is now, before the next Virus-like attack undermines the trust we place in AI.