Exposing the hidden blind spots in AI video perception and the breakthrough method teaching machines to track moving targets.
- The Illusion of AI Vision: While current AI models appear highly capable of analyzing videos, they actually rely on static visual shortcuts—like distinct colors or on-screen symbols—and fail completely when forced to track identical objects moving over time.
- Exposing the Flaw with VET-Bench: A newly introduced diagnostic testbed, VET-Bench, strips away these visual hints, revealing that state-of-the-art AI performs at mere random chance due to inherent mathematical limits in how standard models process continuity.
- The SGCoT Breakthrough: By teaching models to “show their work” and map out object trajectories step-by-step using a technique called Spatiotemporal Grounded Chain-of-Thought (SGCoT), AI can leap from failing grades to over 90% accuracy in visual tracking tasks.

Imagine a street performer shuffling three identical cups across a folding table. For humans, following the cup hiding the ball relies on a basic, innate cognitive skill: visual entity tracking. We simply lock our eyes on the target and follow its continuous movement through space and time. Yet, for all their sophisticated capabilities, today’s Vision-Language Models (VLMs) find this seemingly simple shell game nearly impossible to solve. This glaring deficit in AI perception has long been a critical bottleneck, preventing machines from truly understanding dynamic video content the way humans do.
For a long time, this blind spot was obscured by the very tests designed to measure AI performance. Existing video benchmarks inadvertently provided models with visual shortcuts, allowing them to cheat. For instance, in the Perception Test, shell-game clips often feature distinctive or even transparent cups, allowing an AI to simply re-identify the target based on appearance rather than movement. Similarly, VideoReasonBench includes tracking tasks but superimposes arrows over the frames to indicate swaps. These arrows act as symbolic “swap tokens,” letting the model deduce the answer from static, frame-level cues rather than genuine temporal tracking. In short, AI hasn’t been tracking movement at all; it has been playing a sophisticated game of visual matching.
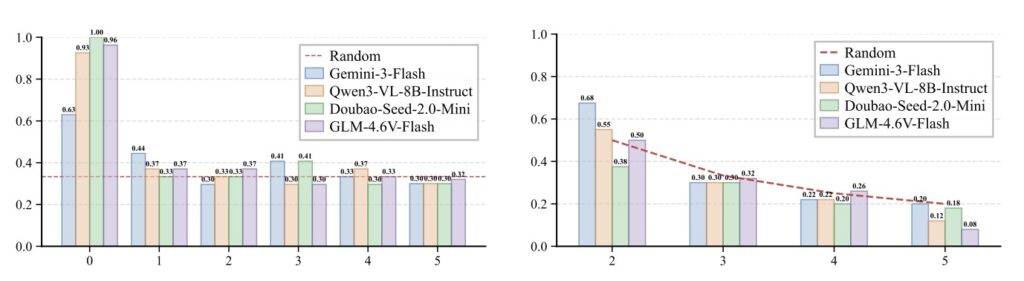
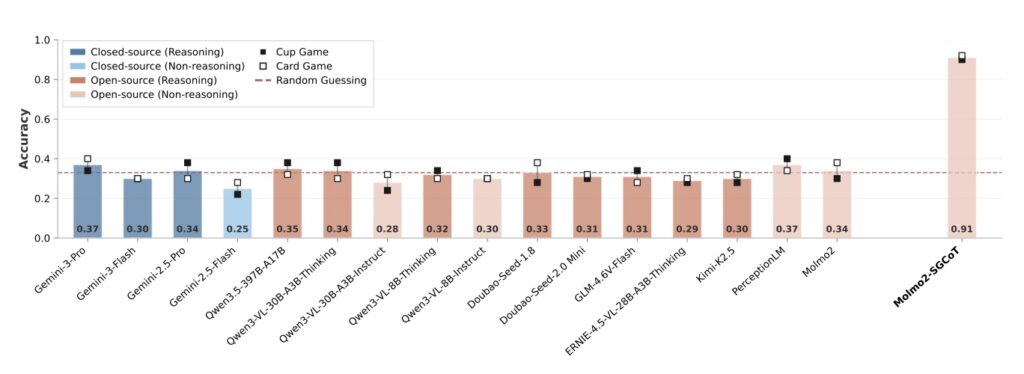
To uncover the truth behind AI video perception, researchers introduced VET-Bench, a synthetic diagnostic testbed rendered using three.js. VET-Bench generates highly varied environments—altering color, lighting, texture, and camera angles—but strictly features visually identical objects. It guarantees that no single frame gives away the target’s identity or the swap operation. The model is forced to rely entirely on fine-grained spatiotemporal continuity. The results were startling: when stripped of their usual appearance cues, current state-of-the-art VLMs performed at or near random chance. The experiment exposed a fundamental limitation in modern AI—an over-reliance on static frame-level features and a complete failure to maintain entity representations as they move through time.

The root of this failure isn’t just a lack of training data; it is a structural mathematical constraint. Theoretical analysis linking this issue to the state-tracking problem proves that visual entity tracking is NC1-complete. This means that fixed-depth transformer-based VLMs simply lack the inherent expressivity required to track indistinguishable objects across multiple frames without intermediate help. Even with massive amounts of training, standard models attempting to solve the shell game in a direct-answer mode hit a hard wall. They physically cannot connect the temporal dots on their own.
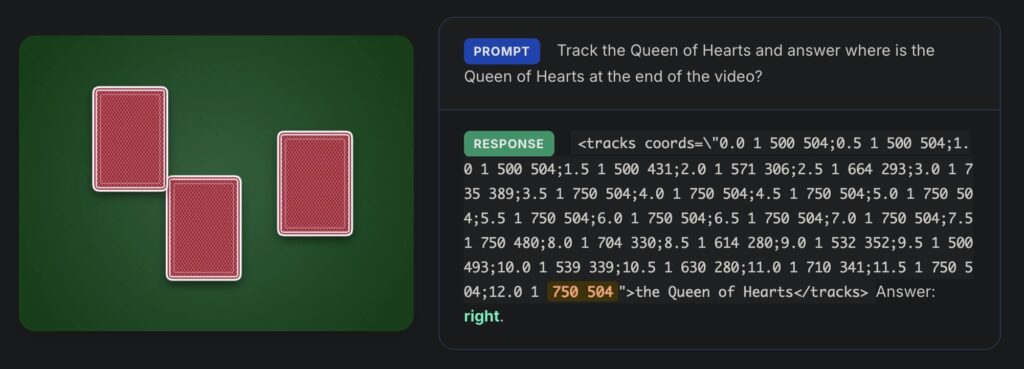
Recognizing the limitation paved the way for a powerful solution: Spatiotemporal Grounded Chain-of-Thought (SGCoT). Instead of forcing the AI to leap directly from the video input to the final answer, SGCoT prompts the model to generate the object’s trajectory as explicit intermediate states. By fine-tuning the VLM Molmo2 on synthesized text-only data to elicit this step-by-step spatial reasoning, researchers achieved a massive breakthrough. By utilizing Molmo2’s object tracking abilities alongside SGCoT, the method achieved state-of-the-art accuracy exceeding 90% on VET-Bench. This proves that with the right reasoning pathway, VLMs can reliably solve the video shell-game task end-to-end without relying on external tools.

While this represents a massive leap forward, the real world remains far messier than a clean, synthetic testbed. Currently, VET-Bench operates in a simplified setting where localizing the object via SGCoT is enough to determine the final answer. Real-world scenarios demand more. They require models to integrate this tracking data with complex visual evidence, such as answering questions based on a specific person’s point of view in the final frames. Furthermore, the real world rarely offers perfect visibility; objects move in close proximity, overlap, suffer from motion blur, and undergo severe occlusion.
Identifying visual entity tracking as a core VLM bottleneck is a crucial step toward creating truly perceptive artificial intelligence. Overcoming the complex hurdles of real-world physics—like occlusion and motion blur—will likely require future models to incorporate stronger physical priors or even comprehensive world models. But by proving that techniques like SGCoT can unlock advanced spatiotemporal reasoning, we are laying the necessary groundwork for a future where AI doesn’t just look at a video, but actually watches and understands it.