A deep dive into Artificial Analysis benchmarks reveals how H100 and B200 systems outpace AMD and Google TPUs in pure cost-per-token performance.
- NVIDIA’s Economic Dominance: Benchmarks show NVIDIA H100 systems achieving a ~5x cost advantage over Google TPU v6e and a ~2x advantage over AMD MI300X when measuring cost per million tokens.
- The Throughput Factor: While hourly rental rates for AMD and Google chips are competitive or cheaper, NVIDIA’s superior throughput at reference speeds results in significantly lower total ownership costs for inference.
- Future Horizons: While current data favors NVIDIA, the landscape is shifting with the impending release of Google’s TPU v7 (Ironwood), promising massive leaps in memory and compute power.
In the high-stakes world of Artificial Intelligence, raw speed is often the headline, but cost efficiency is the bottom line. As enterprises move from training models to deploying them, the cost of inference—actually running the AI to generate answers—has become the primary metric of success. Recent hardware benchmarking by Artificial Analysis offers a revealing look at the current state of the “Chip Wars,” comparing the industry-standard NVIDIA H100 and B200 against challengers AMD MI300X and Google’s TPU v6e (Trillium).
The results paint a clear picture: despite aggressive competition, NVIDIA currently holds a decisive lead in economic efficiency for cloud-based inference.
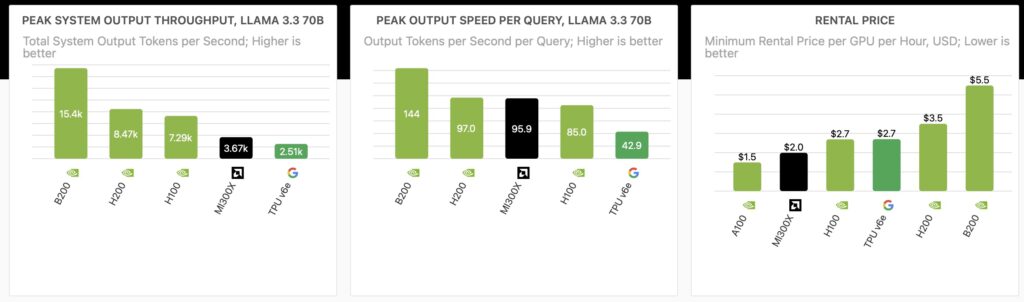
The Real Cost of Intelligence
This metric calculates the cost to process a million tokens while maintaining a responsive speed of 30 output tokens per second (a standard benchmark for user responsiveness).
When putting Llama 3.3 70B—a popular open-weight model—to the test using the vLLM engine, the cost disparity becomes stark:
- NVIDIA H100: $1.06 per million tokens.
- AMD MI300X: $2.24 per million tokens.
- Google TPU v6e: $5.13 per million tokens.
These figures indicate that NVIDIA’s H100 achieves a roughly 2x cost advantage over AMD and a massive ~5x advantage over Google’s TPU v6e. Even the newer NVIDIA B200 systems join the H100 in delivering lower overall costs than the competition.
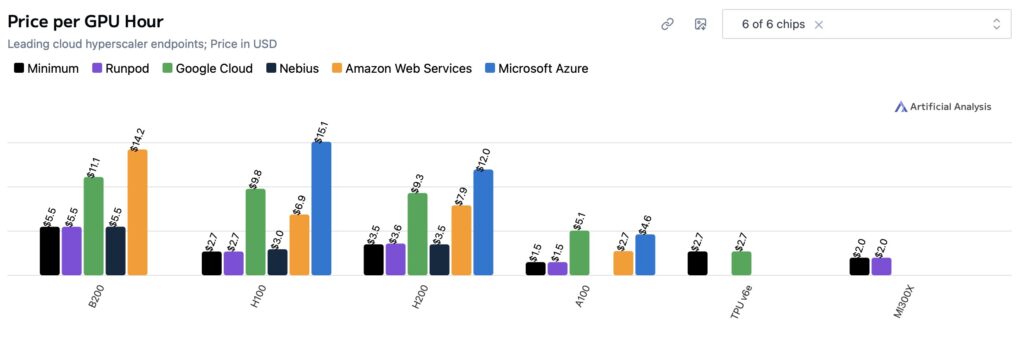
The Hourly Rate Paradox
A surface-level glance at cloud pricing might suggest a different winner. When looking at the lowest available on-demand cloud pricing, the landscape looks highly competitive:
- AMD MI300X: ~$2.00 per chip/hour (Cheapest)
- NVIDIA H100: ~$2.70 per chip/hour
- Google TPU v6e: ~$2.70 per chip/hour
- NVIDIA B200: ~$5.50 per chip/hour
If the TPU v6e costs the same per hour as the H100, why is it five times more expensive per token? The answer lies in system throughput. The NVIDIA systems can process significantly more data while maintaining the required 30 tokens/s speed. Because the H100 churns through requests faster and handles higher concurrency more effectively, users get more “work” out of every dollar spent, rendering the similar hourly rental rate deceptive.
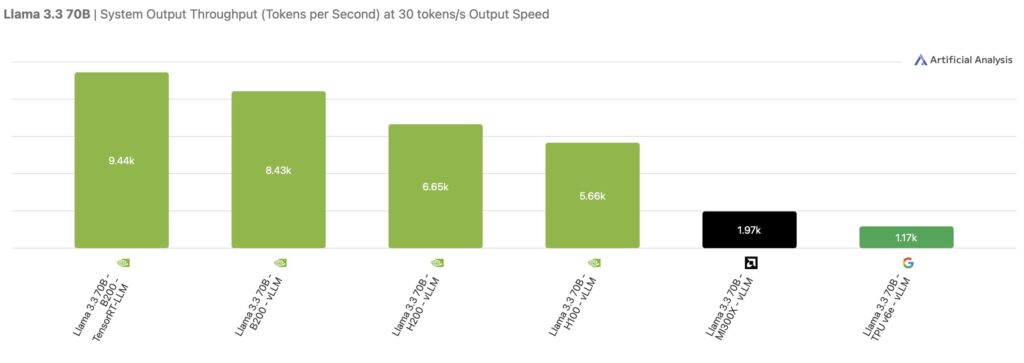
The Software and Ecosystem Gap
The benchmarks also highlight the maturity of the software ecosystems surrounding these chips. NVIDIA’s Hopper and Blackwell systems, along with AMD’s MI300X, were successfully benchmarked across four major models: DeepSeek R1, Llama 4 Maverick, GPT-OSS 120B, and Llama 3.3 70B.
In contrast, results for the TPU v6e are currently reported only for Llama 3.3 70B. This is because it is the only model among the set for which vLLM is officially supported on TPU hardware. This disparity underscores a critical advantage for NVIDIA and AMD: a broader, more flexible software ecosystem that allows for easier deployment across a variety of cutting-edge models.
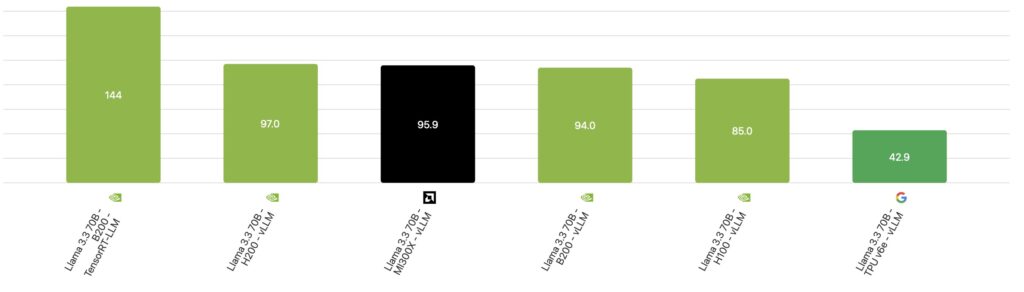
Looking Ahead: The Ironwood Factor
It is important to note that these snapshots represent the market as it stands today, based on widely available cloud rentals. The hardware cycle is moving rapidly. Google’s next-generation TPU v7 (Ironwood) is slated for general availability in the coming weeks and represents a potential paradigm shift.
TPU v7 promises massive specification upgrades over the v6e:
- Compute: Jumping from 918 TFLOPS to 4,614 TFLOPS.
- Memory: Increasing from 32GB to 192GB.
- Bandwidth: Skyrocketing from 1.6 TB/s to 7.4 TB/s.
While these specs suggest the TPU v7 will outperform the v6e substantially, the economic verdict remains out. The “Cost Per Million Tokens” depends entirely on what Google charges for these new instances. Until pricing is announced, the impact on the efficiency leaderboard remains a mystery.
For companies looking to rent cloud capacity for AI inference today, the data suggests that NVIDIA’s ecosystem remains the gold standard for value. By delivering higher throughput per dollar, the H100 and B200 overcome their high hourly sticker prices to offer the lowest cost per token. However, with next-generation silicon from AMD (MI355X) and Google (TPU v7) on the horizon, NVIDIA’s challengers are gearing up for the next round of the efficiency battle.