Bridging Words and Visions to Create Smarter, More Adaptive Agents in a Complex World
- Unified Prediction Framework: Dynalang redefines AI agents by using language not just for instructions, but as a tool to predict future observations, world behaviors, and rewards, creating a self-supervised learning model that grounds diverse language in visual experiences.
- Superior Performance Across Tasks: From grid-world puzzles with helpful hints to navigating photorealistic homes and reasoning over game manuals, Dynalang outperforms traditional reinforcement learning methods by leveraging environment descriptions, corrections, and rules for better decision-making.
- Versatile Capabilities and Pretraining: Beyond acting, Dynalang enables grounded language generation and can be pretrained on text or video datasets without needing actions or rewards, opening doors to offline learning and unified AI architectures for future advancements.
In an era where artificial intelligence is increasingly expected to interact seamlessly with humans and navigate the real world, the challenge lies in equipping agents with a deep understanding of language beyond mere commands. Imagine an AI that doesn’t just follow instructions like “pick up the apple,” but also interprets casual hints such as “the apples are usually in the kitchen” or “watch out for the slippery floor.” This is the vision behind Dynalang, a groundbreaking agent that treats language as a predictive tool, helping it anticipate what comes next in a dynamic environment. By unifying language understanding with future prediction, Dynalang represents a leap forward in creating agents that are not only reactive but proactively intelligent, drawing on diverse linguistic cues to model the world more effectively.

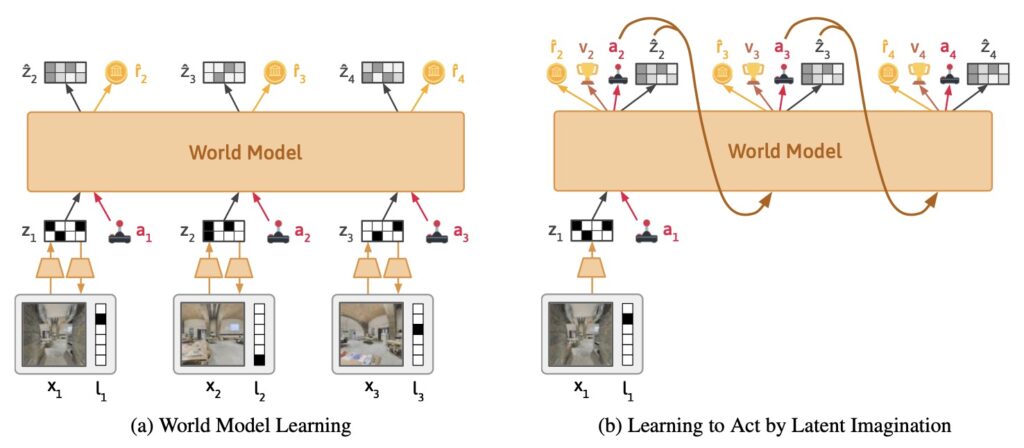
At its core, Dynalang builds on the foundation of DreamerV3, a model-based reinforcement learning (RL) agent, but extends it into a multimodal powerhouse. The system learns continuously from the agent’s interactions in an environment, compressing both text and image inputs at each timestep into a latent representation. From there, it reconstructs the original observations, predicts rewards, and forecasts the next state. This isn’t just about processing data—it’s about intuition. For instance, if the agent reads “the plates are in the kitchen,” it learns to expect visual confirmation of that in future frames, effectively grounding abstract language in tangible visuals. Unlike traditional models that handle text in bulk, Dynalang treats video and text as a single, unified sequence, processing one image frame and one text token at a time. This mirrors human perception, where language unfolds in real-time alongside sights and sounds, enabling more natural learning and even pretraining on text-only datasets like a standard language model.
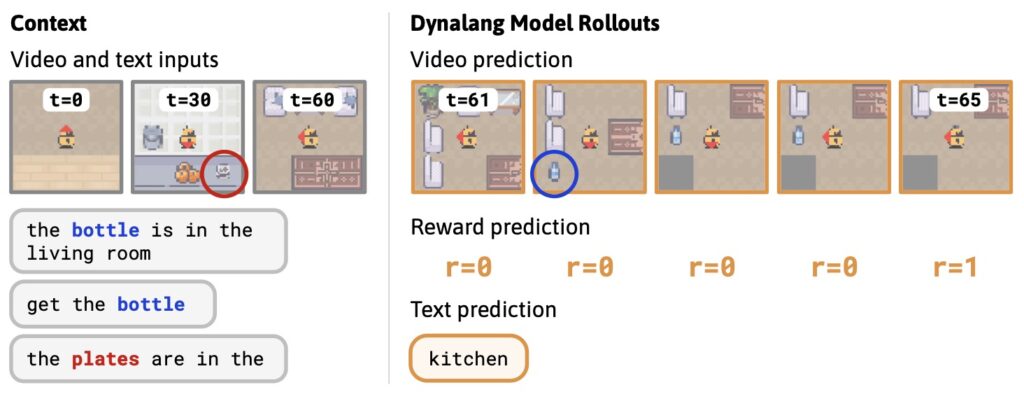
One of the most exciting demonstrations of Dynalang’s prowess is in the newly introduced HomeGrid environment, designed to test agents with “language hints” that go beyond basic instructions. These hints simulate real-world knowledge from humans or texts, including future observations (“The plates are in the kitchen”), interactive corrections (“Turn around”), and dynamics descriptions (“Pedal to open the compost bin”). Without explicit supervision linking text to visuals, Dynalang grounds these hints through its future prediction objective, leading to superior task performance. In experiments, it outshines language-conditioned versions of IMPALA and R2D2, which often falter with non-instructional language and sometimes perform worse when such diversity is introduced. HomeGrid’s release, along with the code, promises to spur further research, encouraging the AI community to explore how agents can leverage everyday language for problem-solving.

Dynalang’s versatility shines even brighter in more complex scenarios, such as the Messenger game environment, where agents must parse lengthy game manuals requiring multi-hop reasoning. Here, the agent combines textual descriptions of episode dynamics with visual observations to identify safe entities for interaction while avoiding dangers. Dynalang not only surpasses IMPALA and R2D2 but also a specialized baseline like EMMA, especially in the toughest stages. Extending this to photorealistic settings, Dynalang excels in Habitat, navigating scanned homes by following natural language instructions. By framing instruction-following as a form of future reward prediction, it unifies these tasks within the same framework, proving that diverse language— from rules to descriptions—can dramatically enhance performance without task-specific tweaks.
What sets Dynalang apart is its generative potential, turning the model into a two-way street where observations influence expected language. In the LangRoom environment, Dynalang generates grounded responses for embodied question-answering by treating language output as part of the action space. This decoupling of world modeling from action learning allows for pretraining on offline datasets of text, video, or both, without needing actions or rewards. For example, pretraining on the TinyStories dataset (2 million short stories) boosts downstream RL performance on Messenger, even outperforming models with pretrained T5 embeddings. Remarkably, Dynalang can generate coherent text rollouts, sampling from latent space to produce stories that, while not yet matching top language models, hint at a future where agents both understand and produce language seamlessly.
From a broader perspective, Dynalang’s approach has profound implications for AI’s role in society. By enabling agents to learn from diverse, unstructured language, it paves the way for more collaborative human-AI interactions—think virtual assistants that anticipate needs based on casual conversations or robots that adapt to real-time feedback in homes and workplaces. This predictive unification addresses limitations in current RL algorithms, which often struggle with language variety, and opens avenues for scalable pretraining on vast datasets. As we move toward agents that truly “model the world with language,” challenges remain, such as improving generation quality and handling even more complex multimodal streams. Yet, Dynalang’s contributions—grounding language via prediction, excelling in diverse tasks, and enabling pretraining and generation—mark a pivotal step toward AI that thinks, acts, and communicates like us. The future of intelligent agents isn’t just about following orders; it’s about understanding the world’s narrative, one word and image at a time.