Google’s fastest and most cost-efficient Gemini 3 series model delivers best-in-class intelligence for high-volume workloads.
- Cost-Effective Scalability: Priced at just $0.25 per 1 million input tokens, Gemini 3.1 Flash-Lite provides developers and enterprises with an affordable way to run high-volume workflows without sacrificing intelligence.
- Unprecedented Speed: Built for real-time responsiveness, it outperforms its predecessor, Gemini 2.5 Flash, with a 2.5X faster Time to First Answer Token and a 45% increase in overall output speed.
- Heavyweight Reasoning: Despite its lightweight tier, the model achieves a 1432 Arena.ai Elo score and excels in complex multimodal understanding, surpassing larger models from prior generations.
The artificial intelligence landscape is evolving rapidly, but a persistent challenge remains for developers and enterprises alike: how to scale high-volume AI workloads without being bottlenecked by prohibitive costs or sluggish latency. In the race to build real-time, responsive applications, organizations often have to choose between speed, affordability, and intelligence. Today, Google is eliminating that compromise with the introduction of Gemini 3.1 Flash-Lite. Rolling out in preview to developers via the Gemini API in Google AI Studio and to enterprises through Vertex AI, this new model is explicitly built to deliver best-in-class intelligence at a massive scale.
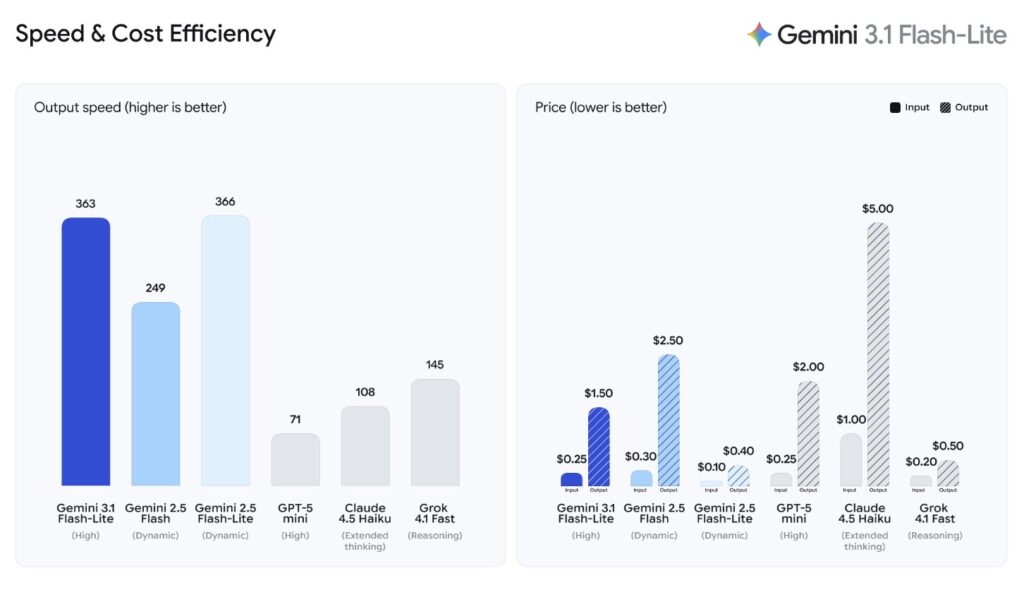
The economics of AI development are shifting, and Gemini 3.1 Flash-Lite is leading the charge by offering cost-efficiency without compromise. High-frequency workflows demand a pricing structure that makes scaling viable. At just $0.25 per 1 million input tokens and $1.50 per 1 million output tokens, 3.1 Flash-Lite delivers enhanced, reliable performance at a mere fraction of the cost of larger models. But affordability is only half the equation; speed is the other. According to the Artificial Analysis benchmark, 3.1 Flash-Lite shatters previous speed limits, outperforming Gemini 2.5 Flash with a 2.5X faster Time to First Answer Token and a remarkable 45% increase in output speed. For developers building consumer-facing apps or dynamic internal tools, this low latency is the missing puzzle piece required to create truly seamless, real-time user experiences.
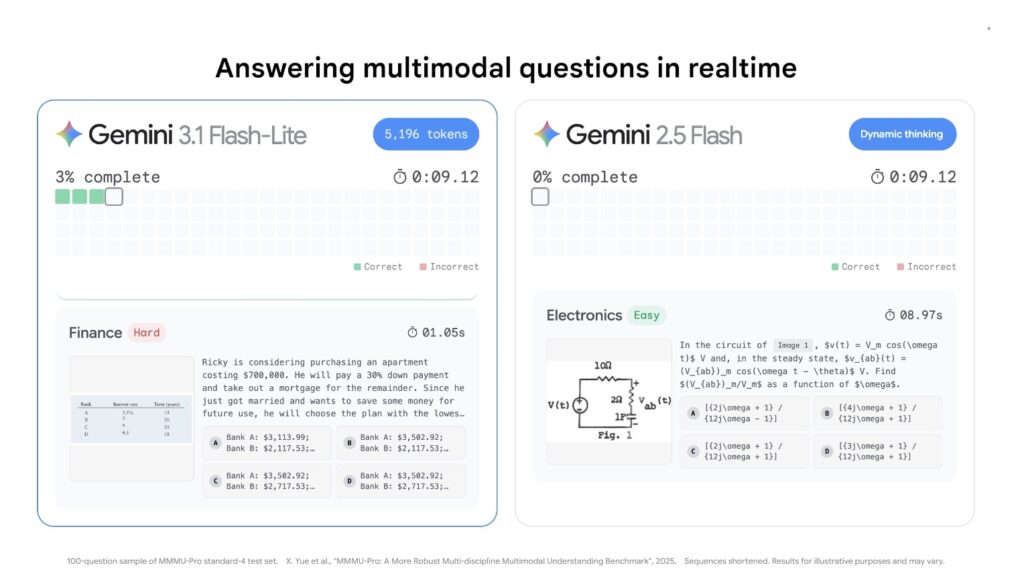
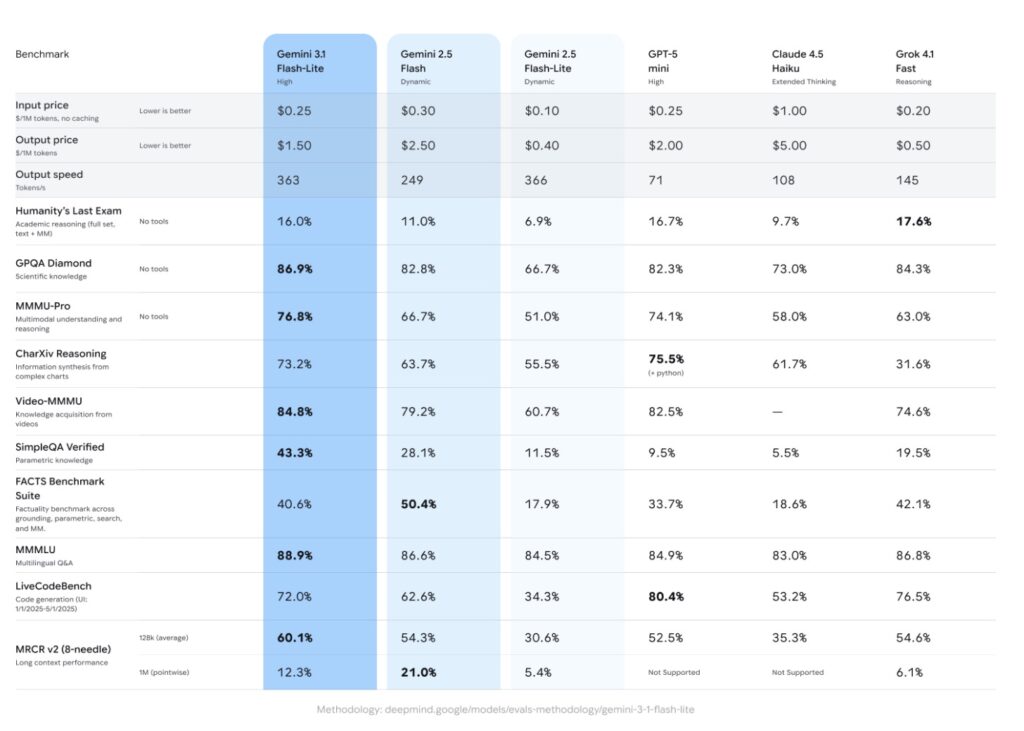
Historically in the AI sector, prioritizing speed and cost meant sacrificing reasoning capabilities and precision. Gemini 3.1 Flash-Lite shatters this paradigm entirely. Despite operating in a lighter model tier, it flexes heavyweight analytical muscles, achieving a highly impressive Elo score of 1432 on the Arena.ai Leaderboard. When put to the test against rigorous reasoning and multimodal understanding benchmarks, the results speak for themselves: it scores 86.9% on GPQA Diamond and 76.8% on MMMU Pro. It not only outperforms other models in its tier but actually surpasses larger, prior-generation models like Gemini 2.5 Flash. This means developers no longer have to deploy massive, expensive models just to ensure complex inputs are understood correctly.
The industry is already taking notice of this paradigm shift. Early-access developers on AI Studio and Vertex AI, alongside forward-thinking companies like Latitude, Cartwheel, and Whering, are actively leveraging 3.1 Flash-Lite to solve complex problems at scale. Early testers have specifically praised the model’s unique blend of efficiency and advanced reasoning. They report that it handles intricate, highly complex inputs with the exact precision traditionally reserved for larger-tier models, all while maintaining strict adherence to provided instructions. By delivering top-tier AI capabilities in a hyper-fast, highly economical package, Gemini 3.1 Flash-Lite isn’t just an incremental update—it is the new foundational engine for the next generation of scalable intelligence.