Breathing Life into Portraits with Dynamic Vocal Avatars
- Expressive Audio-Visual Synchronization: EMO, an advanced audio-driven portrait-video generation framework, crafts vocal avatar videos with rich facial expressions and head movements, syncing perfectly with the rhythm and tone of any input audio, be it talking or singing.
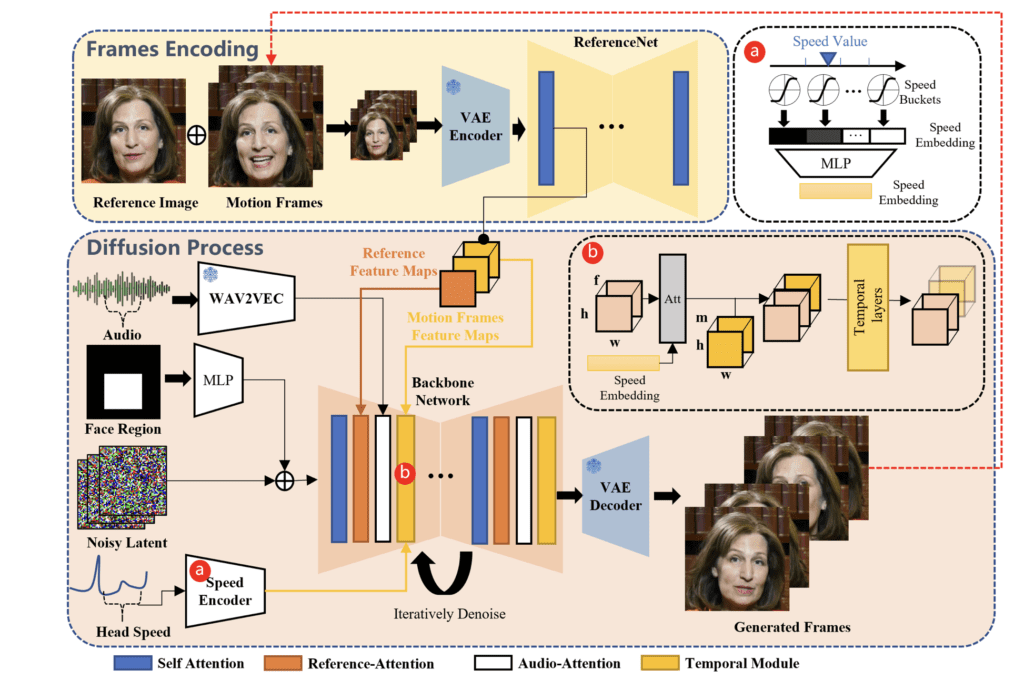
- Innovative Two-Stage Generation Process: The framework employs a novel two-stage process, starting with Frames Encoding to extract crucial features, followed by a Diffusion Process that intricately blends audio embeddings with facial imagery, powered by dual attention mechanisms for identity preservation and motion modulation.
- Versatile and Inclusive Applications: EMO’s technology transcends linguistic and stylistic boundaries, animating portraits from various cultures, languages, and artistic mediums, including historical paintings and 3D models, thereby widening the scope for multilingual character representation in digital media.

In an era where digital interaction and virtual representation are increasingly becoming the norm, EMO emerges as a groundbreaking framework that transforms static portraits into expressive, audio-synced avatar videos. This expressive audio-driven portrait-video generation framework leverages the synergy between vocal audios, such as speech or song, and a single reference image to generate lifelike avatar videos with a spectrum of facial expressions and head poses, adaptable to the duration of the accompanying audio.
The Magic Behind EMO
At the heart of EMO lies a meticulously designed two-stage generation process. The initial Frames Encoding stage utilizes ReferenceNet to extract pivotal features from the reference image and accompanying motion frames. The subsequent Diffusion Process stage is where the audio magic happens; a pre-trained audio encoder processes the vocal embeddings, which, when integrated with a facial region mask and multi-frame noise, orchestrates the facial imagery generation. This stage is crucial for embedding the audio’s emotional and rhythmic nuances into the visual output.

Dual Attention for Dynamic Realism
EMO’s Backbone Network incorporates two distinct attention mechanisms – Reference-Attention and Audio-Attention – to ensure the avatar not only retains the character’s identity throughout the video but also mirrors the dynamic movements dictated by the audio input. Furthermore, Temporal Modules tweak the motion’s tempo, ensuring the avatar’s movements are in perfect harmony with the audio’s pace, from the subtlest expressions to the most energetic rhythms.
Breaking Boundaries in Avatar Animation
What sets EMO apart is its unparalleled versatility and inclusivity. The framework is not confined to contemporary digital portraits; it extends its animating touch to historical paintings, 3D models, and even AI-generated content, infusing them with a new lease on life. This capability opens up a world of possibilities, from animating portraits of historical figures to enabling movie characters to deliver monologues in a multitude of languages and styles, thereby enhancing character portrayal in an increasingly global and diverse cultural landscape.
EMO stands as a beacon of innovation in the realm of digital avatars, redefining the boundaries of how we perceive and interact with digital representations. As we venture further into the digital age, EMO’s contribution to the field of expressive avatar videos promises to enrich our virtual experiences, making digital interactions more immersive, emotive, and universally accessible.